
Page01
Interview

AIディレクターKEITOさんが
セブンのクリエイターPCを使って、
生成AI「Stable Diffusion」で
猫をアニメ風にしてみた!
セブンのクリエイターPCを使って、
生成AI「Stable Diffusion」で
猫をアニメ風にしてみた!
Profile
KEITOさん

Profile
KEITOさん
AI × Webディレクター。AIを使ったサービスや仕組みのプロデュースや業務改善に関するコンサルタント業務に従事。講義やセミナーの登壇をはじめ、AIやITに関するアドバイザーを請け負う。生成AIの活用法や新たなツールなどに関する情報をYouTubeやSNSなどでも発信している。
KEITOさんの
SNSはこちら
SNSはこちら



AIの登場に大きな刺激を受け、はじめて AIに触れた翌月に仕事を辞めて AIディレクターに転身したKEITOさん。AIを活用したサービスのプロデュースやAIやITに関する講義やセミナーを精力的に行なうなど、AI普及にも尽力する第一人者です。
今回のインタビューでは、高性能なセブンアールのゲーミングPC×生成AI「Stable Diffusion」を使って、リアルな猫の画像を生成。その画像を元にさらにイラストを生成するといった二段構えの生成にチャレンジしていただきました!
今回のインタビューでは、高性能なセブンアールのゲーミングPC×生成AI「Stable Diffusion」を使って、リアルな猫の画像を生成。その画像を元にさらにイラストを生成するといった二段構えの生成にチャレンジしていただきました!

subjectAIの登場によって受けた衝撃。
それが AIディレクターへと
歩みを進めた原点
それが AIディレクターへと
歩みを進めた原点
現在、AIのディレクターとして活動されている KEITOさんですが、
改めてご経歴について教えていただけますか?
改めてご経歴について教えていただけますか?
もともとは企業でWebディレクターをしていました。2022年11月にChatGPTが登場してすぐに触れてみたのですが、その技術の高さに衝撃を受けたことをいまでも鮮明に覚えています。当時からディレクターとしての独立志向がありましたが、ChatGPTと出会ったことにより、これを活用すればきっとやっていけるという確信を持ちました。そして、実際にAIディレクターとして独立して現在に至っています。
AIとの出会いがターニングポイントとなったのですね。
ズバリ、独立の決め手になったのは?
ズバリ、独立の決め手になったのは?
そうですね。やはり、YouTubeの配信でしょうか。実際にAIに触れ、その魅力や活用法などを配信したところ、とても大きな反響があり、かなりバズりました。ちょうど生成 AI が世間的にも注目を集めた時期と重なったこともあり、第一人者になれたのかなと思っています。ちなみに独立したのは、はじめてChatGPTに触れた翌月でした。笑
翌月ですか !? 凄まじい行動力ですね。
ChatGPTのリリース直後は手探りで活用されていたと思いますが、
業務においてどのあたりから使い始めましたか?
ChatGPTのリリース直後は手探りで活用されていたと思いますが、
業務においてどのあたりから使い始めましたか?
リリース当時は、まだWebディレクターでしたが、まずはリサーチや資料作成メインで使い始めました。文面はもちろん図表などの作成もAIが全部やってくれる。AIを活用することで業務の効率が高まったのはもちろん、仕事の幅も大きく広がりました。
リサーチや資料作成以外に AI活用の幅を広げていくなかで、
それまでの業務と比べて変化はありましたか?
それまでの業務と比べて変化はありましたか?
Webディレクターって、主にクライアントさんとエンジニアの双方をつなぐ役割を担うことになります。しかし、クライアントさんの主張や想いをそのままエンジニアにぶつけてもカタチにするのは難しく、逆にエンジニアの専門性を持った意見を直接クライアントさんに言ってもなかなか伝わりません。そういった双方の主張を抽象化、いわゆる“ふわっと”させて気持ちよく通すのってとても難しいんですよ。しかし、AIの登場によってその抽象化を完璧にやってくれるようになりました。
お互いを納得させるための橋渡しが簡単にできるようになったということですね。
そうですね。たとえば、エンジニアがPythonのこのコードを使ってなんちゃらすれば、こうできるんですよ。なんて言ってもクライアントさんには伝わりません。しかしAIを活用するとエンジニアの技術的な主張もクライアントさんにしっかり伝わるような資料を作ってくれるんですよね。実際の業務でそれをすべてAIがやってくれたので、もうWebディレクターとしての自分はもういらないのかな。と思ったのと同時に、これを徹底的に活用して独立しよう。って思いましたね。
subject技術の向上が目覚ましい生成AI。
Stable Diffusionなら驚くほど
リアルな画像の生成も可能
Stable Diffusionなら驚くほど
リアルな画像の生成も可能
さて、AIディレクターとして活躍されるKEITOさんですが、
AIの活用についてお聞かせいただけますか?
AIの活用についてお聞かせいただけますか?
もっとも活用しているのは、やっぱりChatGPTになるのですが、生成AIだと Midjourneyや 著作権まわりで安心できるAdobe Fireflyも比較的よく使いますね。エンタメ寄りの画像を生成するときはStable Diffusionを活用しているといった感じです。
生成 AI が登場する以前と登場後で
クリエイター活動に変化はありましたか?
クリエイター活動に変化はありましたか?
先ほども少し触れましたが、クライアントとエンジニアの仲介において、双方の言葉の壁を AIが橋渡ししてくれるようになったのは大きいですね。またイラストなどのクリエイター活動においては、生成AIの精度も上がってきているのでYouTubeやSNSなどの投稿用サムネイルは、外注せずに自分で作るようになりました。

エンタメ系を中心に今回お試しいただく
Stable Diffusionもお使いということですが、
具体的にどんな画像の生成に使っていますか?
Stable Diffusionもお使いということですが、
具体的にどんな画像の生成に使っていますか?
そうですね。例えばキャラクターを作成したり、アニメ風の画像を生成したりするときに使うことが多いですね。
なるほど。では、まずはStable Diffusionを使った
画像生成のプロセスを簡単にお聞かせいただけますか?
画像生成のプロセスを簡単にお聞かせいただけますか?
はい。まずは、Stable Diffusionに対応したモデルの導入ですね。このモデルによってクオリティが大きく変わるので “どのモデルを使うのか” を重視しています。モデルが決まったらプロンプトの作成ですね。
プロンプトって凄く複雑だと思いますすが、
どうやって作成していくのでしょうか?
どうやって作成していくのでしょうか?
まずはChatGPTを活用して基礎的な指示文を作成します。そこから人間の目で確認しながら細かな修正を行ないます。あとは、何度もStable Diffusionで画像を生成し、その都度、プロンプトに調整を加えていくという流れになります。ネガティブプロンプトも同様ですね。生成された画像を見ながら、不要だと思うものや不自然なものを除いていくといった感じです。

プロンプトの作成が重要な作業となるんですね。
そうですね。ゼロの状態から作り出すのは、とても大変な作業になります。しかし、たとえば「黒い猫」を描かせるというプロンプトをある程度完成させたら、それを保存しておくといいですね。ほかの動物に変えたり色を変えたりするなど、プロンプトを少し変えれば使い回すことができますから。
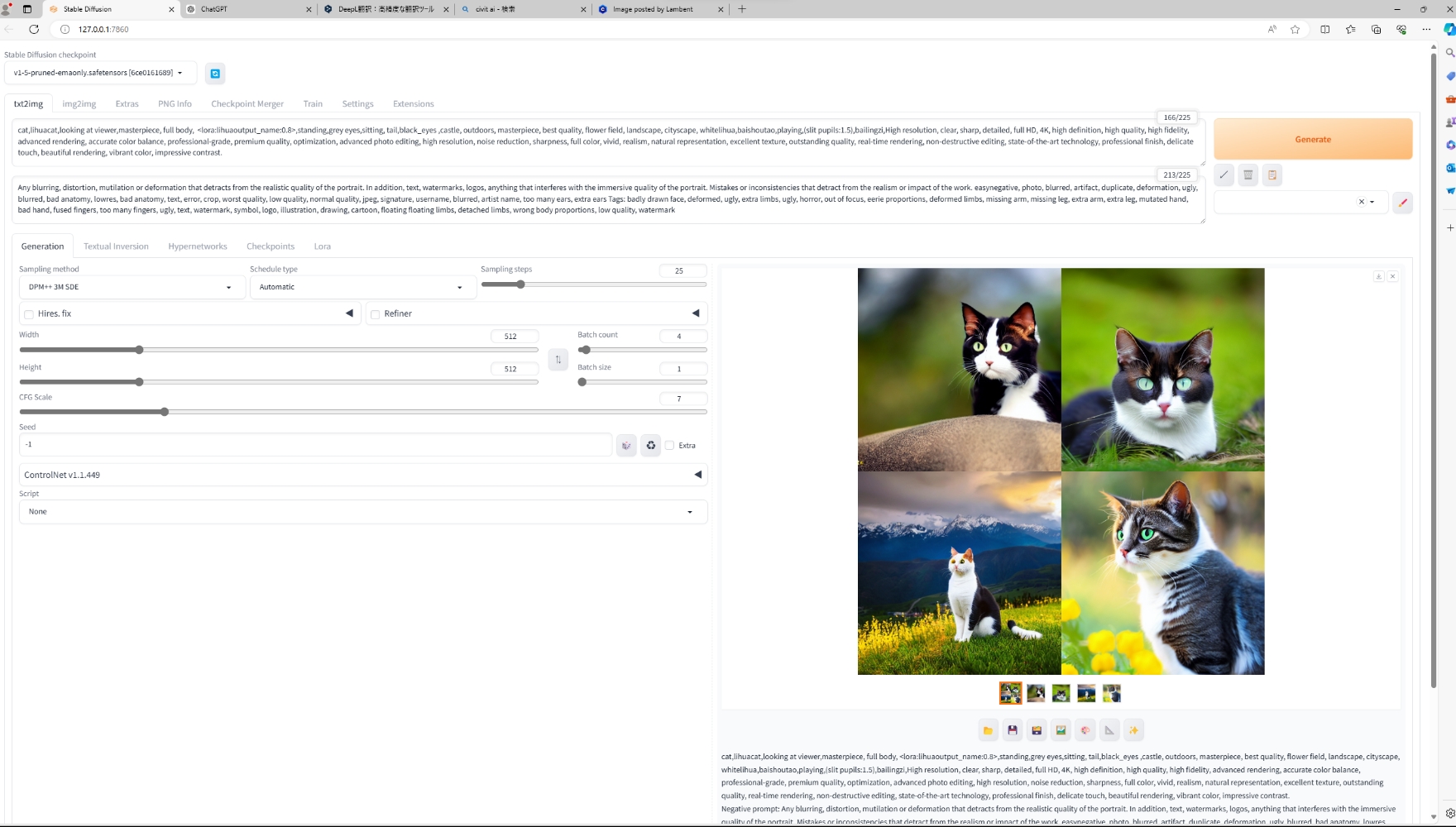
ChatGPTや翻訳ツールを活用しながら、まずはアニメ化のベースとなるリアルな猫の画像を生成しました。ポジティブプロンプトに着目されがちですが、ネガティブプロンプトも細かく記述していくことが成功の秘訣。今回は4枚同時の書き出しですが、セブンアールの高性能ゲーミングPCのおかげであっという間に画像が生成されました。
ChatGPTや翻訳ツールを活用しながら、まずはアニメ化のベースとなるリアルな猫の画像を生成しました。ポジティブプロンプトに着目されがちですが、ネガティブプロンプトも細かく記述していくことが成功の秘訣。今回は4枚同時の書き出しですが、セブンアールの高性能ゲーミングPCのおかげであっという間に画像が生成されました。

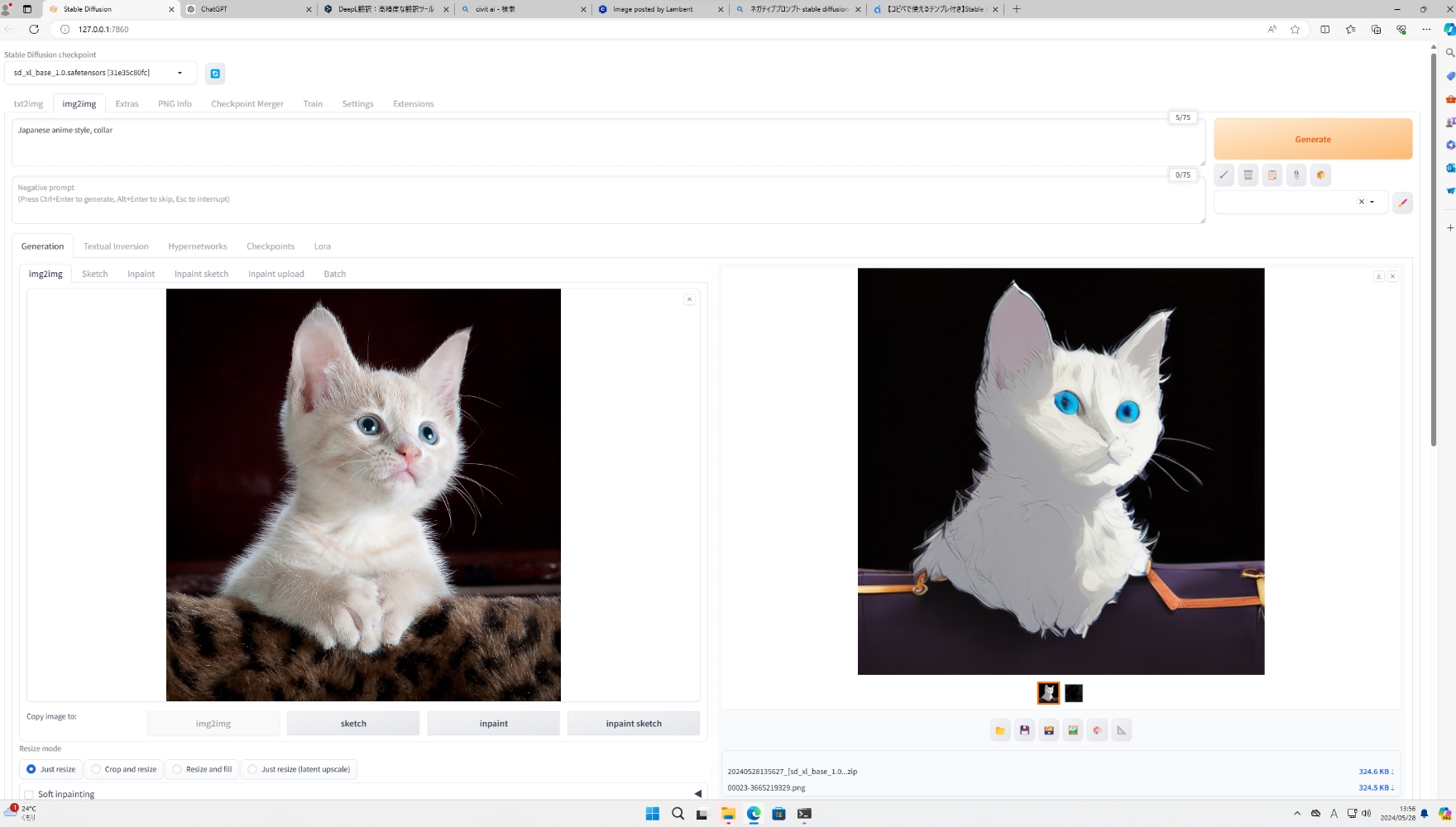
リアルな猫を描いた元の画像(左)からアニメ化した画像(右)を生成。プロンプトと設定ひとつで可愛らしいアニメが完成しました。これなら、イラストを描くのが苦手という人も簡単にイラストが作成できますね!
描画のクオリティを上げるための秘訣はありますか?
プロンプトに8KやRealといったキーワードを入れることでリアルさが増す場合がありますね。あとは、写真のような描き方や古いカメラで撮ったような書き方といった具合に、具体的な指示を出すのもいいかと思います。また、Stable Diffusionの設定で画質そのものを上げることもできるので試してみてはいかがでしょうか。
生成AIは幾度もバージョンアップや学習を繰り返していますが、
Stable Diffusionについてはどうでしょうか?
Stable Diffusionについてはどうでしょうか?
描画のリアルさが圧倒的に進化していると思います。2 年前にAI業界に入ったところは人の顔がぐちゃぐちゃでリアルなものが思ったように描けませんでした。しかし、いまは本格的かつリアルな作品を作ることができており、クオリティの向上が著しいと考えています。

subject生成AIは
ガチャを引き続けるようなもの。
だからこそ、
高性能 PC で効率よく生成
ガチャを引き続けるようなもの。
だからこそ、
高性能 PC で効率よく生成
生成AIを活用して画像を描いていくためには、かなり高性能なPCが必要だと思います。
KEITOさんが業務やクリエイター活動で使用している環境をお聞かせいただけますか?
日常的な業務では、MacBooK Proを使用していますが、生成AIを使って画像や映像を生成するときには自作の Windows 機を使用しています。
ちなみに、どれくらいのスペックのマシンをお使いなのでしょう?
生成AIを動かすための自作PCで言うと……。CPUは、第 13 世代インテル® Core™ i7 プロセッサーで、GPUに関してはNVIDIAのGeForce RTX 4070 Tiを搭載したモデルを使用しています。
今回の検証で使わせてもらった PC は、自分の PC よりも新しい世代の インテル® Core™ i7 プロセッサー (第 14 世代)搭載だったので、より素早く生成してくれたと思います!
今回の検証で使わせてもらった PC は、自分の PC よりも新しい世代の インテル® Core™ i7 プロセッサー (第 14 世代)搭載だったので、より素早く生成してくれたと思います!
かなり高性能なモデルを使用していますね。
どうしても、生成 AI は PC に大きな負荷が掛かりますからね。実際に同じプロンプトを使って Stable Diffusion で描画をさせてみても、本当に様々なパターンの画像が生成されます。その画像を見ながらプロンプトを調整して、また生成を繰り返す。言ってみれば、ガチャを延々と引き続けるようなものですね。笑
そのガチャが当たるまで引き続けるんですね。笑
そうなんですよ。そのガチャを1回引くのにどれだけの時間がかかるか。それが、PC の性能によって大きく変わってきますね。今日、使わせてもらったセブンアールさんの PC だと、4枚の画像を生成するのに僅か10秒くらいしか掛かりませんでしたね。やっぱり、このスピード感って大切だと思うんですよ。
塵も積もれば山となる。ですね。
そう。1度で4枚の画像を生成したところで、納得できるものって絶対出てこないので、それを100回、200回と繰り返していくことになるのですが、PCの性能によって費やす時間が全然違いますからね。
それが業務となれば、生産効率が全く違いますね。
生成AIのメリットってなに? って考えた時に、それまでクリエイターが時間をかけて創っていたものを誰でも素早くできる。といったことが挙げられると思うんですよね。だから、遅いPCを使って時間をかけて生成してしまうと、メリットを最大限に活かせなくてもったいないと思います。生成AIで描画を始めようとする人のなかには副業で稼ぎたい。という人もいるかもしれませんが、遅いPCだと時給換算すると残念なレベルになってしまうことも十分にありますね。
やっぱり、最初から高性能なPCを持っておいたほうがいいということですね?
そうですね。高性能なモデルを使えば、生成速度が上がるのは言うまでもありませんね。業務や副業として稼ぐことを考えても、時給が一気に倍になるといっても過言ではないですね。だから、PCの本体価格だけを見ると高額に見えてしまうかもしれませんが、、投資する価値は十分にあると思いますね。
KEITOさんが考える生成AIを使うためのPCに
求められる性能についてお聞かせください。
求められる性能についてお聞かせください。
やっぱり、CPUに関しては インテル® Core™ i7 プロセッサー (第 14 世代) もしくは インテル® Core™ i9 プロセッサー (第 14 世代)は欲しいですよね。より高速さを求めるなら インテル® Core™ i9 プロセッサー (第 14 世代)搭載がいいですね。
Stable Diffusionを使用するときは、ChatGPTや翻訳ソフトなども立ち上げることがあるので、コア数が多いモデルだと、ひとつひとつの動作が早くなるのでストレスなく作業ができるのも大きいです。あと、搭載モデルは少ないですけど、AIに特化した インテル® Core™ Ultra プロセッサーも楽しみですね。
GPUに関してはNVIDIAのGeForce RTX4070 Ti以上を選びたいところですが、価格がややネックですね。例えば、予算を抑えてStable Diffusionを楽しみたいなら、 インテル® Arc™ グラフィックスを選ぶのもアリだと思います。
アップデートによってStable Diffusionはもちろん、ローカル環境で使う際に必要になる「AUTOMATIC 1111」にも対応しているので動作に対する不安はなく、コスパにも優れると思います。さらにコスパを重視するなら、十分快適に使える インテル® Core™ i5 プロセッサー (第 14 世代)と組み合わせるといいかもしれませんね。
Stable Diffusionを使用するときは、ChatGPTや翻訳ソフトなども立ち上げることがあるので、コア数が多いモデルだと、ひとつひとつの動作が早くなるのでストレスなく作業ができるのも大きいです。あと、搭載モデルは少ないですけど、AIに特化した インテル® Core™ Ultra プロセッサーも楽しみですね。
GPUに関してはNVIDIAのGeForce RTX4070 Ti以上を選びたいところですが、価格がややネックですね。例えば、予算を抑えてStable Diffusionを楽しみたいなら、 インテル® Arc™ グラフィックスを選ぶのもアリだと思います。
アップデートによってStable Diffusionはもちろん、ローカル環境で使う際に必要になる「AUTOMATIC 1111」にも対応しているので動作に対する不安はなく、コスパにも優れると思います。さらにコスパを重視するなら、十分快適に使える インテル® Core™ i5 プロセッサー (第 14 世代)と組み合わせるといいかもしれませんね。
今回の検証機を提供いただいたセブンアールさんも
高性能で魅力的なPCを多数ラインナップしていますが、
注目したモデルはありますか?
高性能で魅力的なPCを多数ラインナップしていますが、
注目したモデルはありますか?
そうですね。クリエイター/動画編集向けの『EFFA』シリーズや性能重視のゲーミング PC 『ZEFT Gaming PC』シリーズなら、どの製品を選んでも十分に Stable Diffusion で画像生成が楽しめると思います。しかし、もし動画の生成を考えるなら、生成に非常に大きな負荷が掛かるので、グラフィックボードをGeForce RTX4080以上をもしくは インテル® Arc™ GPUを選んでカスタムするなど、より高性能な構成にしておくことをおすすめします。
そのほかにも、今回使ったPCについて感想はありますか?
とにかく音が静かでしたね! そして配線もほとんど見えていなくてスッキリしています。これなら効率的に熱が排出できるので、大きな負荷をかけた時の動作も安心だと思います。

subject進化を続けるAIは決して
脅威ではなく便利なツール。
それを世に広く伝えたい
脅威ではなく便利なツール。
それを世に広く伝えたい
さて、最後にAIの今後についてお伺いします。進化が目覚ましいAIの世界ですが、
これからのAIに期待することは?
これからのAIに期待することは?
そうですね。AIって便利なのに、いまひとつ普及が実感できていないのかなと思っています。もちろん、様々なシステムやサービスに活用されていますが。AIが組み込まれている機器は増えてきていますが、これからは、当たり前のようにPCやスマホなどの機器に組み込まれ、活用されていくともっと身近な存在になっていくと思います。
便利な一方で、まだ成長期と言えるAIが抱える課題感などについて
お聞かせいただけますか。
お聞かせいただけますか。
それってなかなか難しい問題だと思います。生成AIって便利であり世の中を変えていくツールのひとつである一方で言い方が難しいですけど、脅威と捉えられたり毛嫌いされたりする方もいらっしゃいますね。そういった方達との向き合い方が課題になってくるのではないかと思います。
今後、社会とAIは必ず共存していくことになりますからね。
そうですね。AIの使用に対する倫理面というかリテラシーをしっかり普及していくこと。そして、AIは、決して脅威ではないという事を広く世間に伝えていくことが大切なのではないかなと思っています。
今日はありがとうございました!
subjectKEITOさんが体験した
セブンアールの『EFFA E47IM』を詳しくご紹介
セブンアールの『EFFA E47IM』を詳しくご紹介


PCショップセブンアールがプロデュースするクリエイター/動画編集向けのデスクトップ PC『EFFA E47IM』。清潔感とシンプルさが際立つホワイトを基調とした PCケースやファン、グラフィックボードを採用。広い角度から PCの内部が見渡せるよう、設計された2面強化ガラスがクリエイターの高揚感と好奇心を刺激。

通常多くは上部に配置する電源スイッチやUSB Type-Cポートをケースのフロント下部に集約しておりデザインへの意識の高さを感じられる。インテル® Core™ i7 プロセッサー (第 14 世代)の搭載に加え、NVIDIAのGeForce RTX 40シリーズの搭載によってフルHDの動画制作や生成AIによる創作活動などのクリエイティブ活動も快適にこなせます。
Page02
画像生成AIの使い方
今話題となっている画像生成AI、「Stable Diffusion」をローカル環境で利用するための、おすすめPCについて解説します。ローカル環境で実行するにあたって推奨されるPCスペックから、導入手順などを実機でのスクリーンショットを交えて解説しますので、これからStable Diffusionを利用したい方は最後までご覧になってください。
急成長している
「生成AI」とは?
「生成AI」とは?
近年になって急成長している分野の一つとして、「生成AI」というものがあります。AI=人工知能という言葉自体は古くから知られていますが、現在の生成AIはAI自身が学習するというのが特徴の一つです。
例えば今日において代表的な生成AIのひとつ「ChatGPT」は、テキストで答えを出力します。ただこのChatGPTも当初から高精度での回答を出していたわけではなく、事前に入力されていたデータに加えて、ユーザーからの過去の質問などをデータとして学習した結果、精度が常に高められていったのです。
例えば今日において代表的な生成AIのひとつ「ChatGPT」は、テキストで答えを出力します。ただこのChatGPTも当初から高精度での回答を出していたわけではなく、事前に入力されていたデータに加えて、ユーザーからの過去の質問などをデータとして学習した結果、精度が常に高められていったのです。

生成AIを取り巻く課題
生成AIはデータを取り込むことで、その精度を高めることができます。ただし学習の過程で間違ったデータを取り込んでしまう、あるいは膨大なデータを学習することによる問題もあります。
例えばChatGPTの場合では、情報源そのものが間違い・デマであったとき、ChatGPTも間違ったテキストを出力してしまいます。確かにChatGPTはテキスト生成において情報の精査を行いますが、一定の確率で人間と同様にエラーを出してしまうのです。
また膨大な学習データが武器であるAIは、既に一人の人間では太刀打ちできないほどの速度で結果を出してしまうので、将来的には既存の産業や雇用に対して大きな影響を与えるとされています。
例えばChatGPTの場合では、情報源そのものが間違い・デマであったとき、ChatGPTも間違ったテキストを出力してしまいます。確かにChatGPTはテキスト生成において情報の精査を行いますが、一定の確率で人間と同様にエラーを出してしまうのです。
また膨大な学習データが武器であるAIは、既に一人の人間では太刀打ちできないほどの速度で結果を出してしまうので、将来的には既存の産業や雇用に対して大きな影響を与えるとされています。
画像生成AI
『Stable Diffusion』とは?
『Stable Diffusion』とは?
今回取り上げる『Stable Diffusion』も生成AIの一種ですが、その特徴は写真やイラストなどの画像を出力することに特化しているということです。
ChatGPTでもテキストで条件を指定すれば画像を出力することも可能ですが、細かい部分まで指定するのは難しいです。それに対してStable Diffusionは細かい画風などに関しても、追加データを使うことで変化させることが可能となっています。
ChatGPTでもテキストで条件を指定すれば画像を出力することも可能ですが、細かい部分まで指定するのは難しいです。それに対してStable Diffusionは細かい画風などに関しても、追加データを使うことで変化させることが可能となっています。
利用方法はWebアプリケーションと
ローカルの2種類
ローカルの2種類
Stable Diffusionはオープンソースとなっており、誰でも利用可能となっています。ただ実際にStable Diffusionを動かすには、高い処理能力を持った高性能PCなどを用意する必要があります。
そこでStable Diffusionを利用する際には、処理能力をクラウドサーバなどの外部に委託する方式の「Webアプリケーション環境」と、自前で高性能なPCを用意する「ローカル環境」の二つの利用方法が考えられます。
そこでStable Diffusionを利用する際には、処理能力をクラウドサーバなどの外部に委託する方式の「Webアプリケーション環境」と、自前で高性能なPCを用意する「ローカル環境」の二つの利用方法が考えられます。

それぞれの環境によってメリット・デメリットがあります。
Webアプリケーション環境はクラウド環境とも言われ、外部サーバーに画像生成の処理能力を借りる形になります。そのため外部サーバーの所有者から利用する際に制約や検閲、利用料の請求などが発生します。
一方のローカル環境では、生成AIに必要な処理能力を持った高性能PCを自前で揃えるための初期導入コスト、技術的なトラブル発生時の自己解決能力などの、経済的・技術的ハードルが高い傾向にあります。言い換えれば自己責任が伴う分、他者からのしがらみなどは少なくなります。
Webアプリケーション環境はクラウド環境とも言われ、外部サーバーに画像生成の処理能力を借りる形になります。そのため外部サーバーの所有者から利用する際に制約や検閲、利用料の請求などが発生します。
一方のローカル環境では、生成AIに必要な処理能力を持った高性能PCを自前で揃えるための初期導入コスト、技術的なトラブル発生時の自己解決能力などの、経済的・技術的ハードルが高い傾向にあります。言い換えれば自己責任が伴う分、他者からのしがらみなどは少なくなります。
生成される画像の特徴と課題
画像生成AIも生成AIの一種であるため、事前入力されたデータ+追加で得られていく学習データによって、より精度が高い成果物を出力できるようになっていきます。画像生成AIの場合は写真やイラストなどの画像をデータとして扱っており、それぞれの画像の特徴などをAIが学習して、特徴的な画風などを再現できるようになっています。
言い換えればデータ元となる写真やイラストを取り込んでいるため、そのデータ元の画像を制作したクリエイターの権利や名誉を害する恐れがあるというのが、画像生成AIの課題の一つとして取り上げられることが多いです。具体的なケースとして「特定のイラストレーターの画風を学習したAIで、贋作を大量に作成して一般に公開する」というものがあり、模倣した絵をバラ撒くことでイラストレーターの社会的信用などを害しているケースも見受けられます。
また中国では「非公式のウルトラマンの生成画像を商業利用していた」として、円谷プロダクションから著作権侵害を訴えた裁判があり、こちらは円谷プロダクションの訴えが認められ損害賠償金の支払い命令が出ています。この様に著作権上の問題などが取り沙汰されることが多い画像生成AIですが、「基本的には個人利用の範疇であれば、著作権侵害などの問題を起こすことはない」ということも覚えておいてください。
言い換えればデータ元となる写真やイラストを取り込んでいるため、そのデータ元の画像を制作したクリエイターの権利や名誉を害する恐れがあるというのが、画像生成AIの課題の一つとして取り上げられることが多いです。具体的なケースとして「特定のイラストレーターの画風を学習したAIで、贋作を大量に作成して一般に公開する」というものがあり、模倣した絵をバラ撒くことでイラストレーターの社会的信用などを害しているケースも見受けられます。
また中国では「非公式のウルトラマンの生成画像を商業利用していた」として、円谷プロダクションから著作権侵害を訴えた裁判があり、こちらは円谷プロダクションの訴えが認められ損害賠償金の支払い命令が出ています。この様に著作権上の問題などが取り沙汰されることが多い画像生成AIですが、「基本的には個人利用の範疇であれば、著作権侵害などの問題を起こすことはない」ということも覚えておいてください。
Stable Diffusion の
ローカル環境への導入
ローカル環境への導入
「他者からの制約を受けない、自由な画像生成環境を構築したい」と思われている方には、ローカル環境への導入がベストな選択となります。
導入にあたって「高い処理能力を持つ高性能PC」が必要であることは既に述べた通りですが、Stable Diffusionが上手く処理を任せるための条件というのが存在します。この条件を満たしていないとPCスペックが上手く活用されず、生成時間が長期化したりエラーを起こす原因となります。
導入にあたって「高い処理能力を持つ高性能PC」が必要であることは既に述べた通りですが、Stable Diffusionが上手く処理を任せるための条件というのが存在します。この条件を満たしていないとPCスペックが上手く活用されず、生成時間が長期化したりエラーを起こす原因となります。
高性能GPUを搭載したデスクトップPC推奨
Stable Diffusionの処理をローカル環境で行うには、以下の様な条件があります。

2024年5月時点でStable Diffusionを動作させるのに適したPCスペックを考える上で、まずGPUが中核を担ってきます。より高性能なGPUほど生成時間などが少なくて済むのですが、その分消費電力や発熱も大きくなり、加熱するGPUを冷やすための冷却機構も大型化します。そのため大きな冷却機構を組み込めるデスクトップPCが有利となるのです。
CPUに関しては画像生成時の処理のほとんどをGPUに依存しているため、特別な指定はありません。ただGPUは画像生成AIだけでなく、ゲームや動画編集等への利用方法もあるので、そういった用途でも使うことも考えれば「Intel Core i7~i9」辺りを採用するとバランスが良いでしょう。
メモリやストレージに関しては、大きなデータを扱う様になるので大きな容量が必要となります。ただデスクトップPCの場合は増設もし易いので、この点でも有利と言えます。
CPUに関しては画像生成時の処理のほとんどをGPUに依存しているため、特別な指定はありません。ただGPUは画像生成AIだけでなく、ゲームや動画編集等への利用方法もあるので、そういった用途でも使うことも考えれば「Intel Core i7~i9」辺りを採用するとバランスが良いでしょう。
メモリやストレージに関しては、大きなデータを扱う様になるので大きな容量が必要となります。ただデスクトップPCの場合は増設もし易いので、この点でも有利と言えます。
「VRAM容量12GB以上のGPU」が
推奨される理由
推奨される理由
Stable Diffusionによる描画において中核を担うGPUですが、こちらは何を使ってもいいというわけではなく、快適に活用するためには条件が付きます。
まず、後ほど紹介することになる「AUTOMATIC 1111」を使う環境下では、Stable Diffusionが推奨する12GB以上のVRAM(ビデオメモリ)容量を持った製品を選ぶこと。それ以下の容量しか持たないGPUを選択すると、描画速度が低下するだけでなく、そもそも動作しなかったり描画が正常に行えない可能性があるため注意が必要です。12GBや16GBといったVRAM容量を持つGPUを選ぶことで、より快適で高いパフォーマンスが期待できます。
以上のことから、最低でも12GBのVRAM容量を持つNVIDIA製もしくはインテル® Arc™ グラフィックスを選びましょう。
まず、後ほど紹介することになる「AUTOMATIC 1111」を使う環境下では、Stable Diffusionが推奨する12GB以上のVRAM(ビデオメモリ)容量を持った製品を選ぶこと。それ以下の容量しか持たないGPUを選択すると、描画速度が低下するだけでなく、そもそも動作しなかったり描画が正常に行えない可能性があるため注意が必要です。12GBや16GBといったVRAM容量を持つGPUを選ぶことで、より快適で高いパフォーマンスが期待できます。
以上のことから、最低でも12GBのVRAM容量を持つNVIDIA製もしくはインテル® Arc™ グラフィックスを選びましょう。
今後は最適化が進むことで
環境構築の選択肢が広がる
環境構築の選択肢が広がる
近年半導体メーカーであるNVIDIA社の株価が急上昇しているのは、「AIの処理に適したGPUを製造している」ということ と関係しています。 それ以前は仮想通貨マイニングなどでGPUの需要が高まりましたが、 2024年時点での生成AI事情に関してはNVIDIA社GPU一強状態となっています。 ただしAIへの関心の高まりに対して、 他の半導体メーカーでも様々なアプローチが行われています。
例えば、インテル社が製造する「 インテル® Arc™ グラフィックス」に搭載される、 インテル® Xe スーパーサンプリング・テクノロジー (XeSS) もAIを活用したアプローチのひとつ。このソリューションは、 インテル® Arc™ グラフィックス製品に内蔵された専用マシンラーニング・ハードウェアと AIアルゴリズムによって画質の最適化を実現するというもの。Stable Diffusionのバージョンアップなどによって、この インテル® Arc™ GPUでの動作がスムーズになっています。特に後述するWEB UI「AUTOMATIC 1111」 での動作性が確保されたことは、Stable Diffusionでの画像生成におけるPC環境の選択肢が広がったことを意味しています。
例えば、インテル社が製造する「 インテル® Arc™ グラフィックス」に搭載される、 インテル® Xe スーパーサンプリング・テクノロジー (XeSS) もAIを活用したアプローチのひとつ。このソリューションは、 インテル® Arc™ グラフィックス製品に内蔵された専用マシンラーニング・ハードウェアと AIアルゴリズムによって画質の最適化を実現するというもの。Stable Diffusionのバージョンアップなどによって、この インテル® Arc™ GPUでの動作がスムーズになっています。特に後述するWEB UI「AUTOMATIC 1111」 での動作性が確保されたことは、Stable Diffusionでの画像生成におけるPC環境の選択肢が広がったことを意味しています。
こうしたGPUの変革だけでなく、グラフィックボードを搭載するPCそのものの処理速度をアップさせることも生成AIを快適に利用するための第一歩。 インテル® Core™ i7 プロセッサー (第 14 世代) 搭載 PC なら、パフォーマンス重視のマルチコア「P-Core」と省電力性を重視したシングルコアの「E-core」を搭載することで、Stable Diffusionをはじめとする生成AI使用時はパワフルに。そして、日常使いでは経済的にといった具合にメリハリのある動作で効率的なPC利用をサポートしてくれます。
この様にハードウェアとソフトウェア双方がAIを意識したつくりになっていることに加え、双方の相性問題も日々改善が進んでおり、今後ますます生成AIが身近な物として普及すると思われます。
この様にハードウェアとソフトウェア双方がAIを意識したつくりになっていることに加え、双方の相性問題も日々改善が進んでおり、今後ますます生成AIが身近な物として普及すると思われます。

今回使用する
「EFFA E47IM」について
「EFFA E47IM」について


今回はローカル環境での検証用PCとして「EFFA E47IM」を使用します。
こちらのモデルはゲーミングPCのカテゴリーであると同時に、32GBのメモリを搭載したことでクリエイティブ用途での利用にも適しています。重要となるGPUに関しても、16GBのVRAMを搭載したRTX4070Ti SUPERとなっており、
Stable Diffusionに適した構成となっています。
こちらのモデルはゲーミングPCのカテゴリーであると同時に、32GBのメモリを搭載したことでクリエイティブ用途での利用にも適しています。重要となるGPUに関しても、16GBのVRAMを搭載したRTX4070Ti SUPERとなっており、
Stable Diffusionに適した構成となっています。
ゲーミングPCとしての利用も可能
EFFA E47IMはゲーミングPCでもあるということで、もちろんPCゲーム用途でも高いフレームレートを出してくれます。RTX4070Ti SUPERは4070シリーズの中でも後期モデルとなります。12GBだったVRAMが16GBに増えているほか、GPUそのものも性能向上が図られ、上位モデルであるRTX4080に迫るスペックを持ち合わせています。
PCの電力設定
画像生成時にはGPUに大きな負荷がかかり、必要とされる電力も大きくなります。そのためGPUへの供給電力を最大化し、性能を引き出すための電力設定を行います。まずWindowsの設定からコントロールパネルを経由して電力オプションを開き、「高パフォーマンス」を選択します。稀に非表示になっていることもありますが、追加プランの部分に隠れていることが多いです。
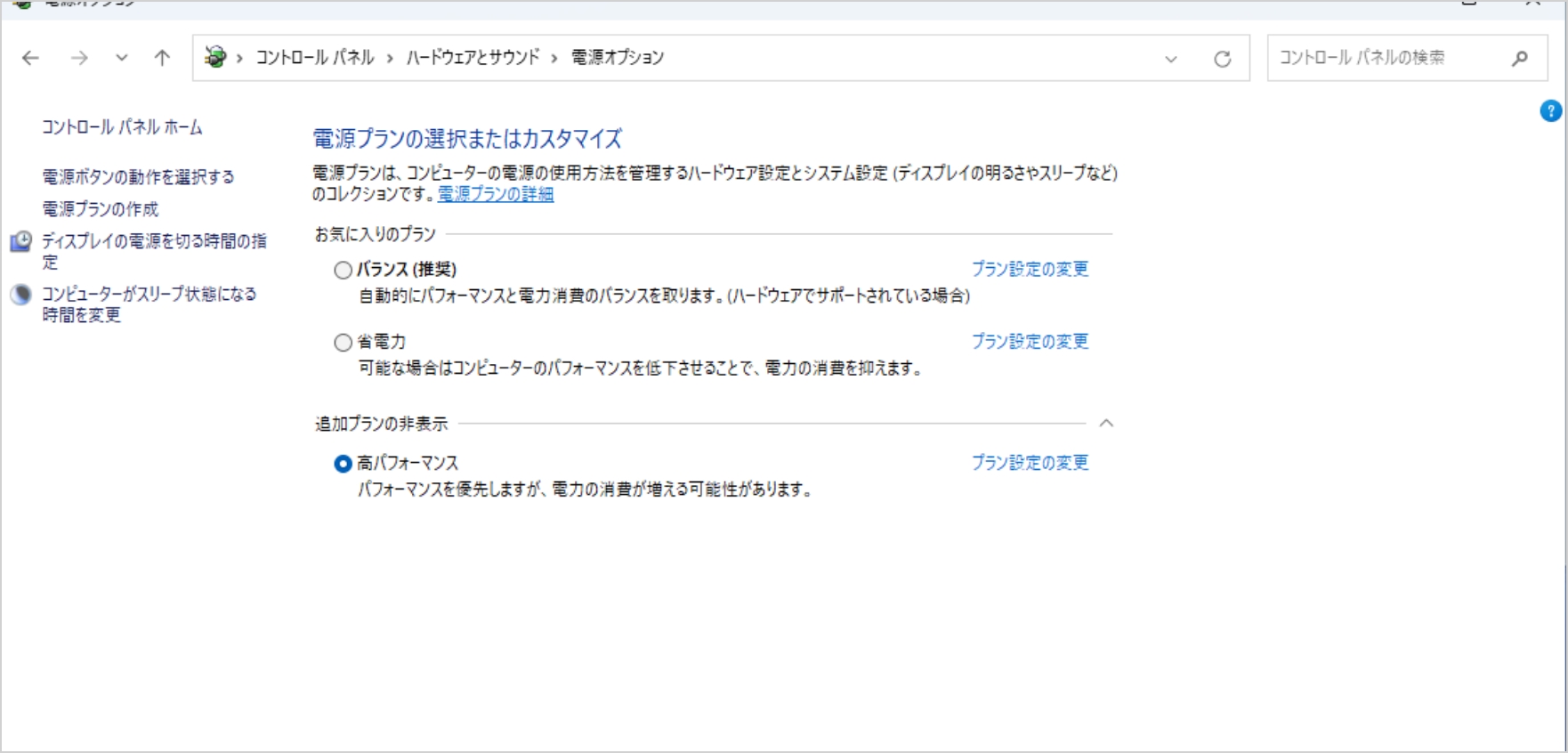
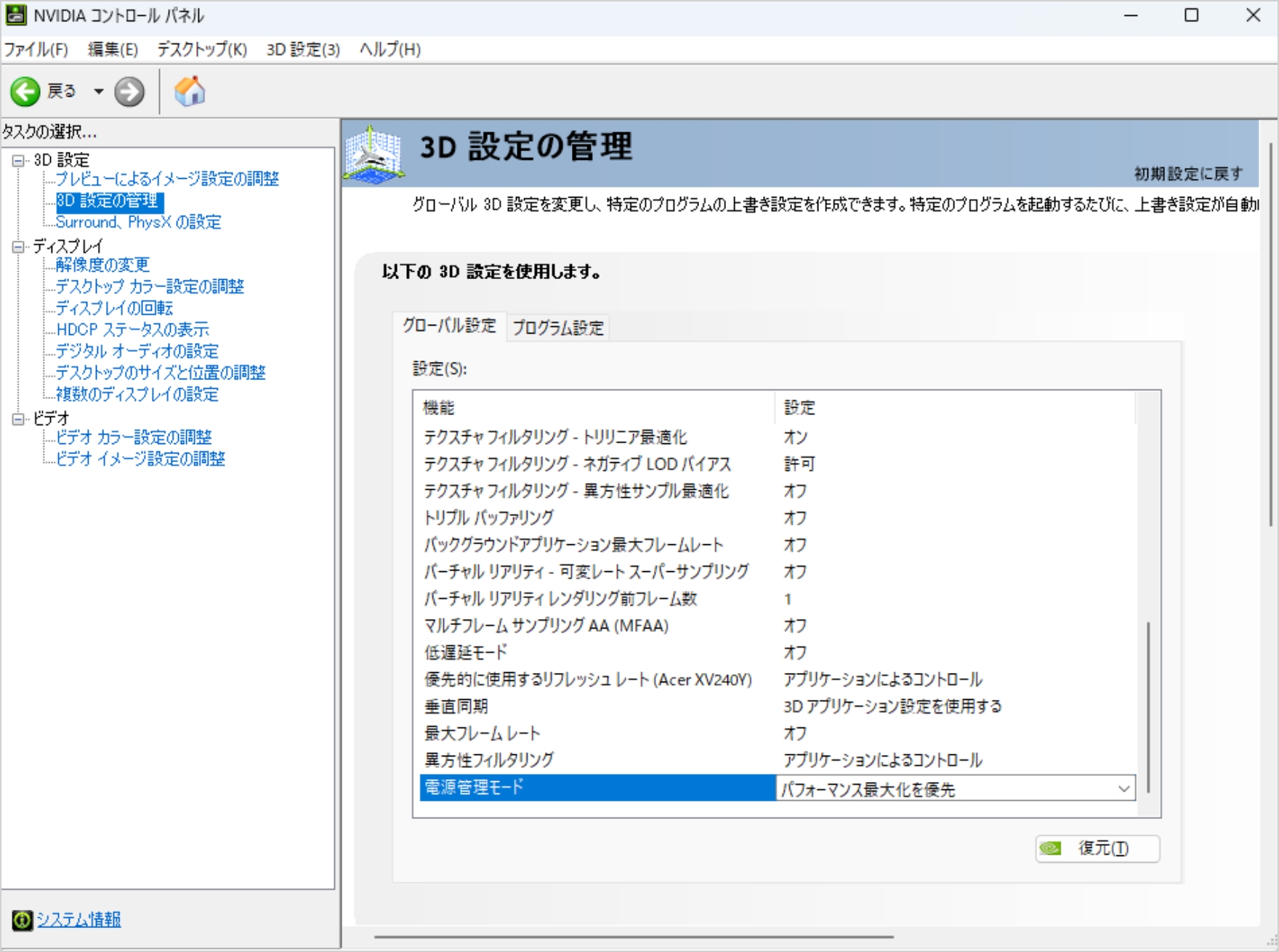
次にホーム画面で右クリック→NVIDIAコントロールパネルを開き、3D設定の管理のグローバル設定から電力管理モードを「パフォーマンス最大化を優先」を選択します。
ローカル環境PCへの
『Stable Diffusion』導入手順
『Stable Diffusion』導入手順
次にローカル環境へのStable Diffusionの導入手順について紹介します。今回はStable DiffusionをWeb UIで表示する「AUTOMATIC 1111」を利用します。
以下の3つをインストールしていきます。
Python(3.10.6)
git
Stable Diffusion
Python(3.10.6)のインストール
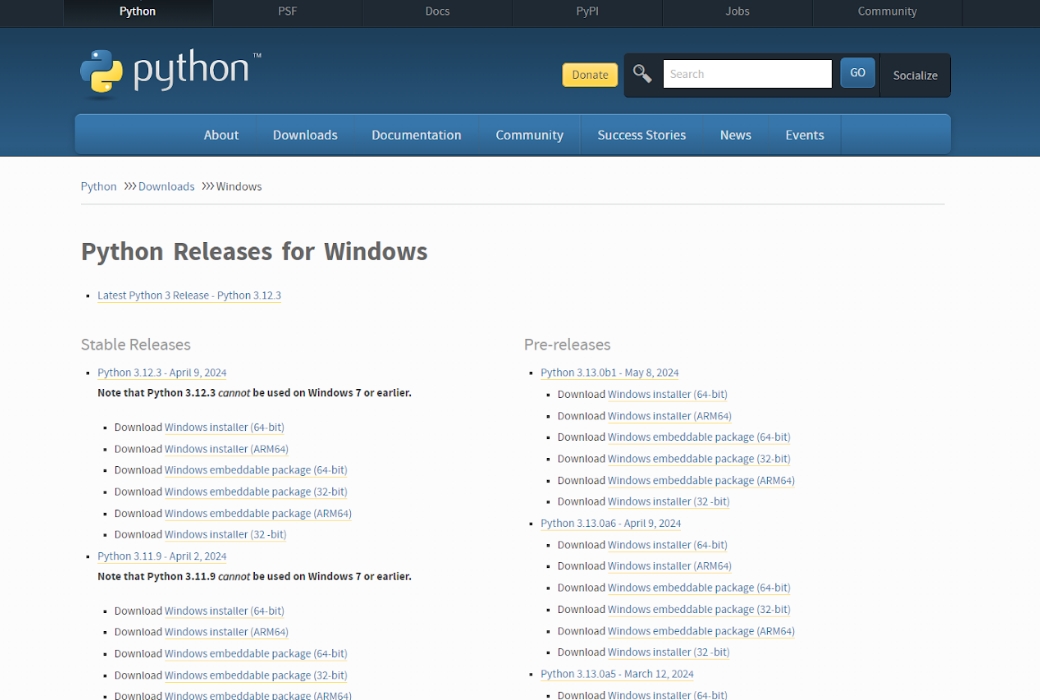
Stable Diffusionを動かす際にはPythonを利用します。ただ、Pythonであれば何でもいいというわけではなく、「Python3.10.6」でなければ正常な動作環境が得られません。
-
Pythonの公式サイトにアクセスし、下にスクロールしていくと「Python3.10.6」の欄がでてきます。
-
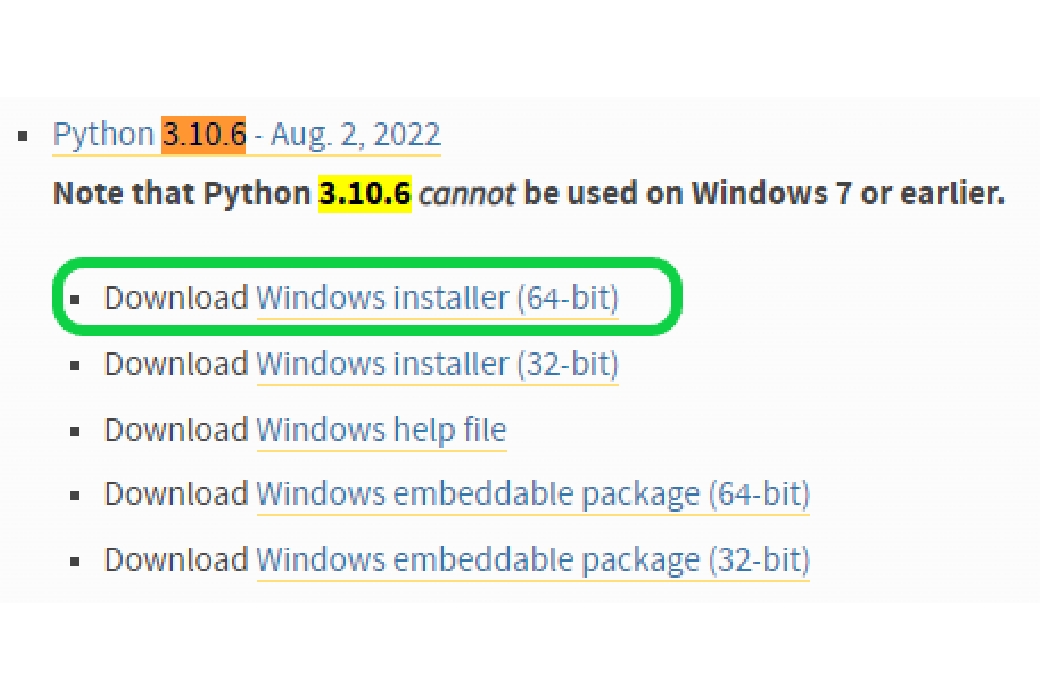
この中の「Download Windows installer (64-bit)」をクリックしてインストールを開始しますします。
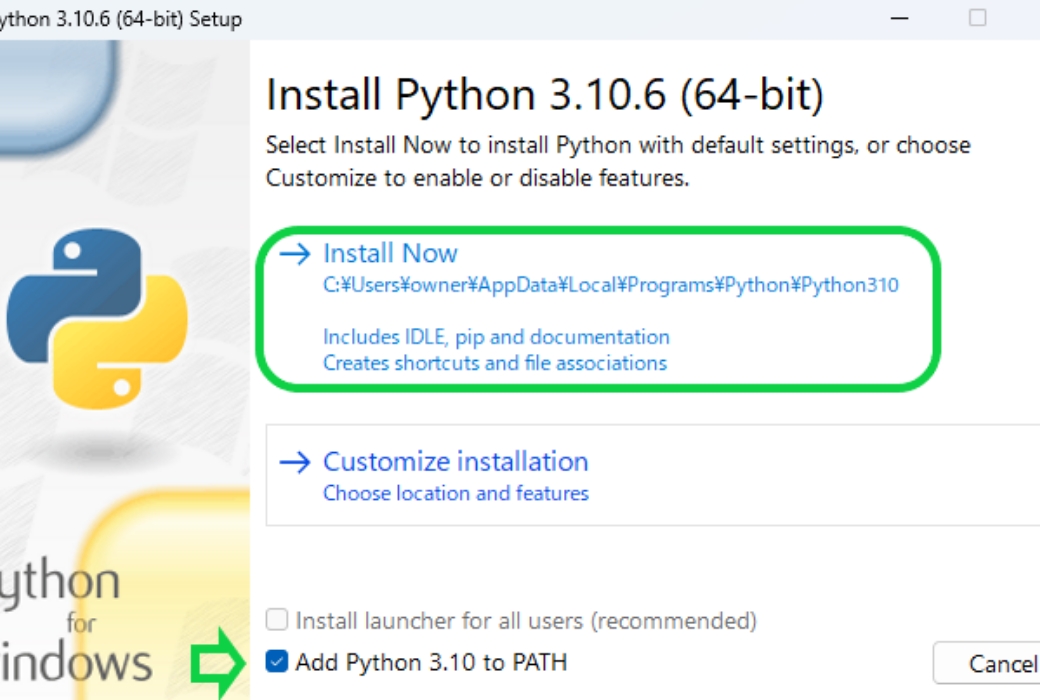
-
インストーラーが起動したら、「Add Python 3.10 to PATH」にチェックを入れてから、「Install Now」をクリックしてインストールを開始します。
-
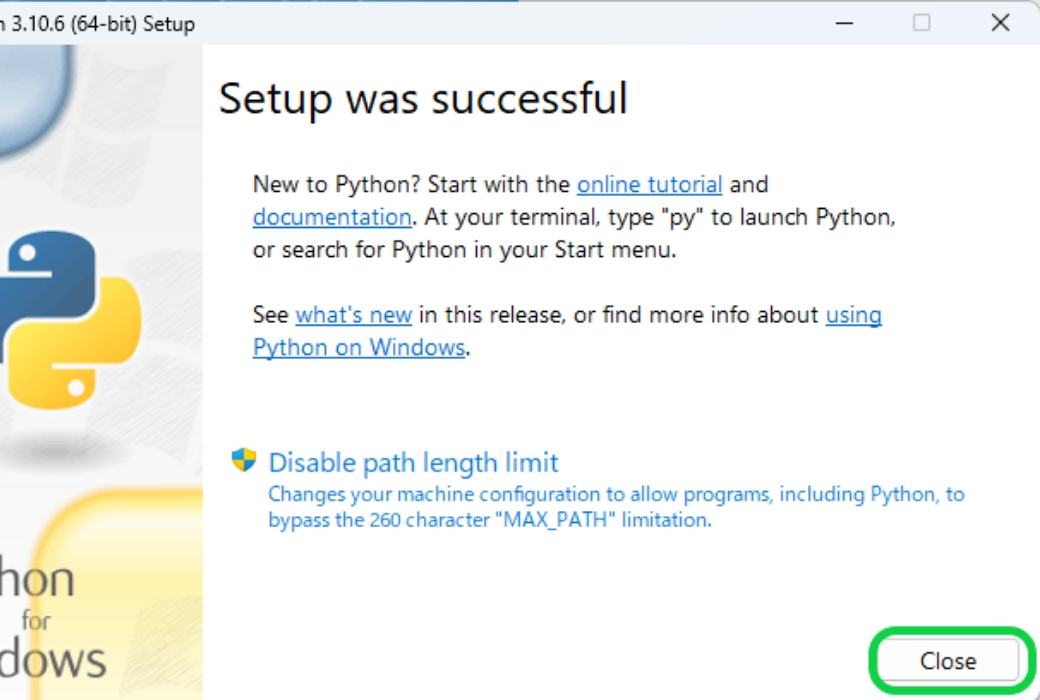
インストールが完了すると、上のような画面が表示されるので「Close」で閉じます。
-
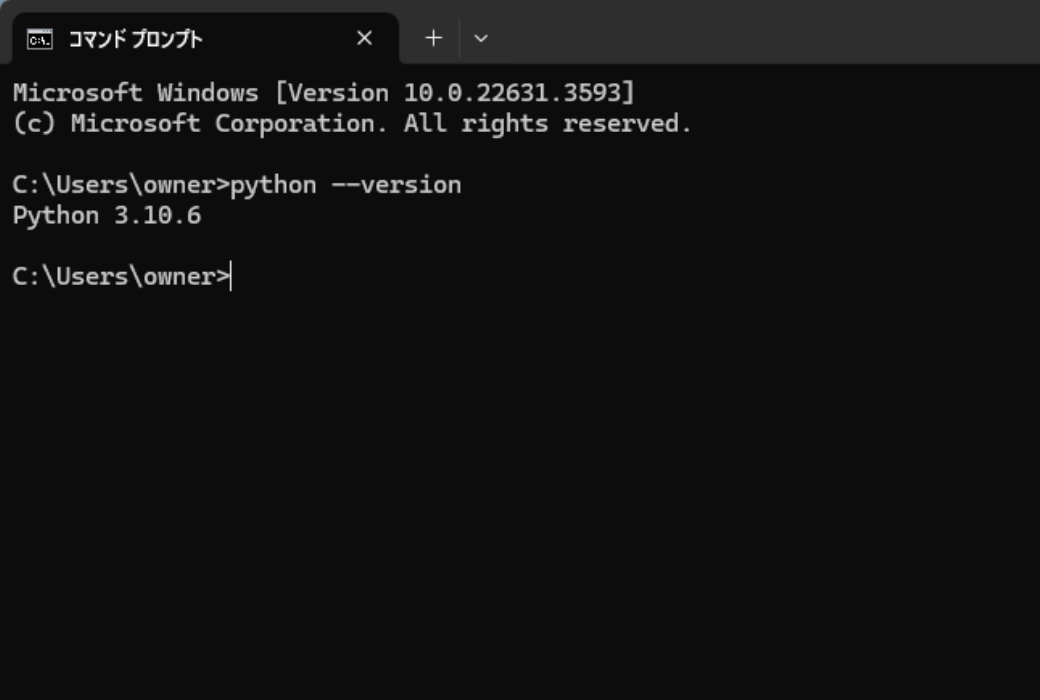
確認としてコマンドプロンプトを実行し、「python —version」と入力することで、pythonのバージョンを確認することができます。 この時にpythonのバージョンが違っていたり、あるいはバージョンが表示されない時はアンインストールしてやり直ししてください。
gitのインストールGitはプログラムのファイル管理をするためのシステムとなります。
-
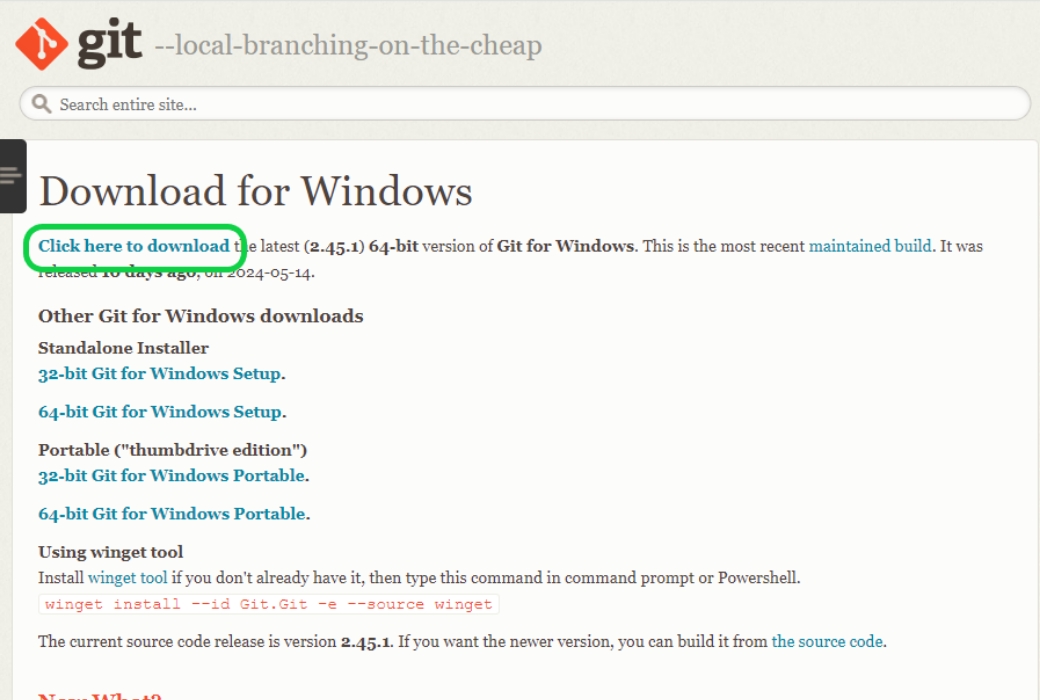
公式サイトの「Click here to download」をクリックします。
-
セットアップのためのインストーラーが起動しますので、この後いくつかの画面が出るのでNextもしくはinstallを押していきます。
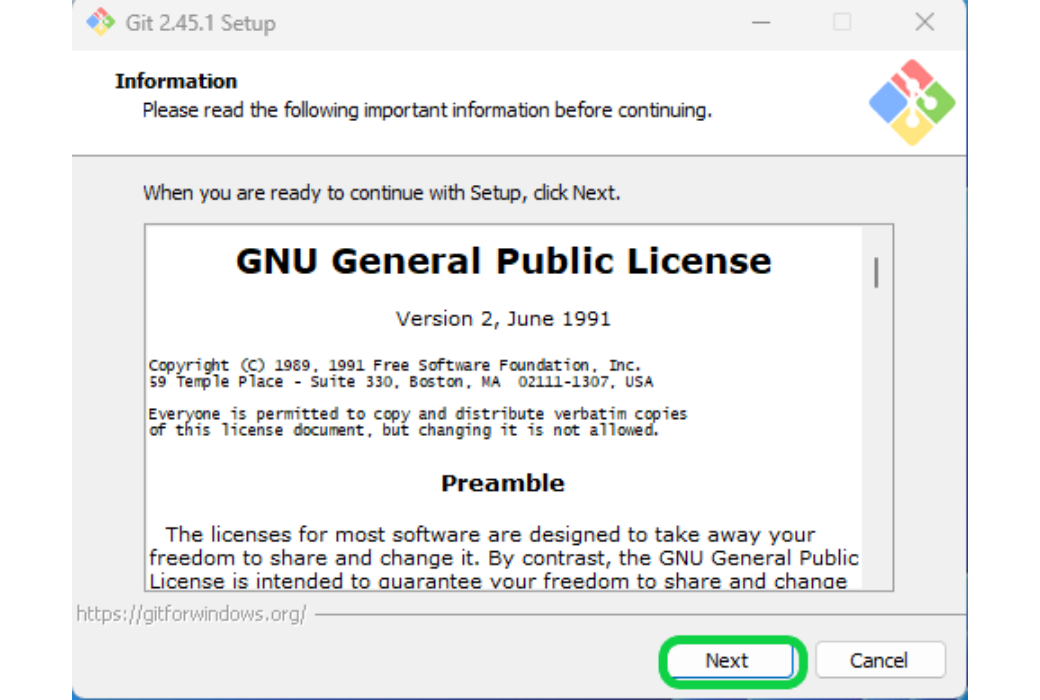
-
インストールが完了したらこのような画面に変わるので、「Finish」をクリックして画面を閉じます。どのアプリケーションで開くかという画面が出ましたら、普段使っているWebブラウザを指定してください。
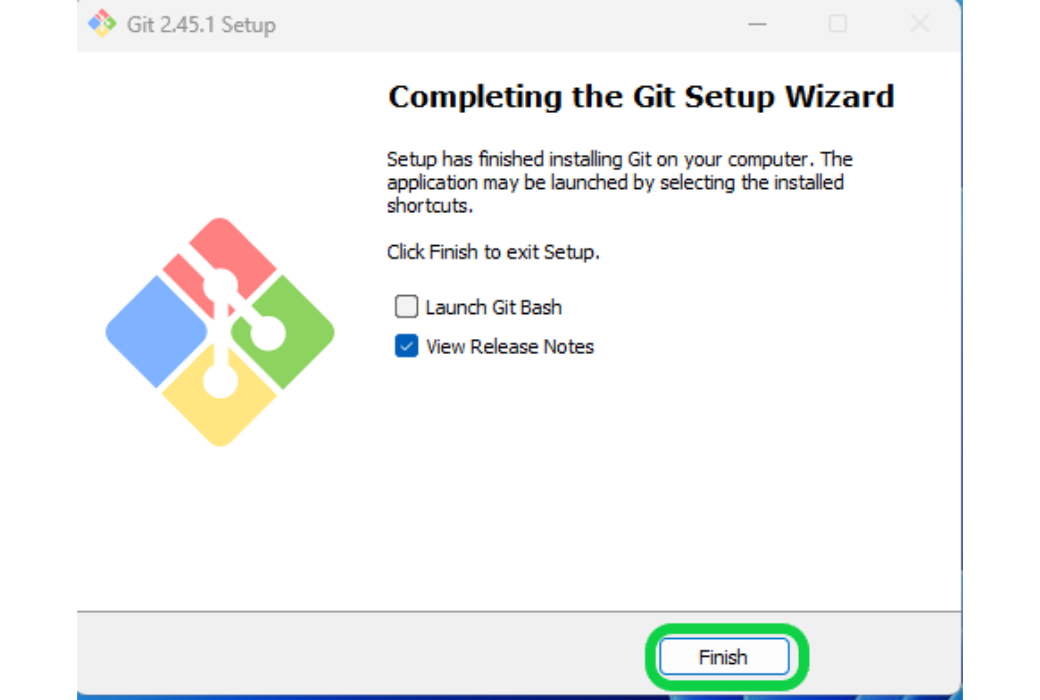
-
するとブラウザ上にパッチノートに関するサイトが開きますが、閉じてしまって大丈夫です。
Stable Diffusionのインストール
-
大きな空き容量のあるストレージを用意し、インストールするフォルダを作成。作成したフォルダ上で右クリック→「Open Git Bash here」をクリックします。Open Git Bash hereが見えない場合は、「その他のオプション」をクリックすると表示されます。後述するモデルなどの導入も考慮すると、ストレージ容量は大きい方が良いです。
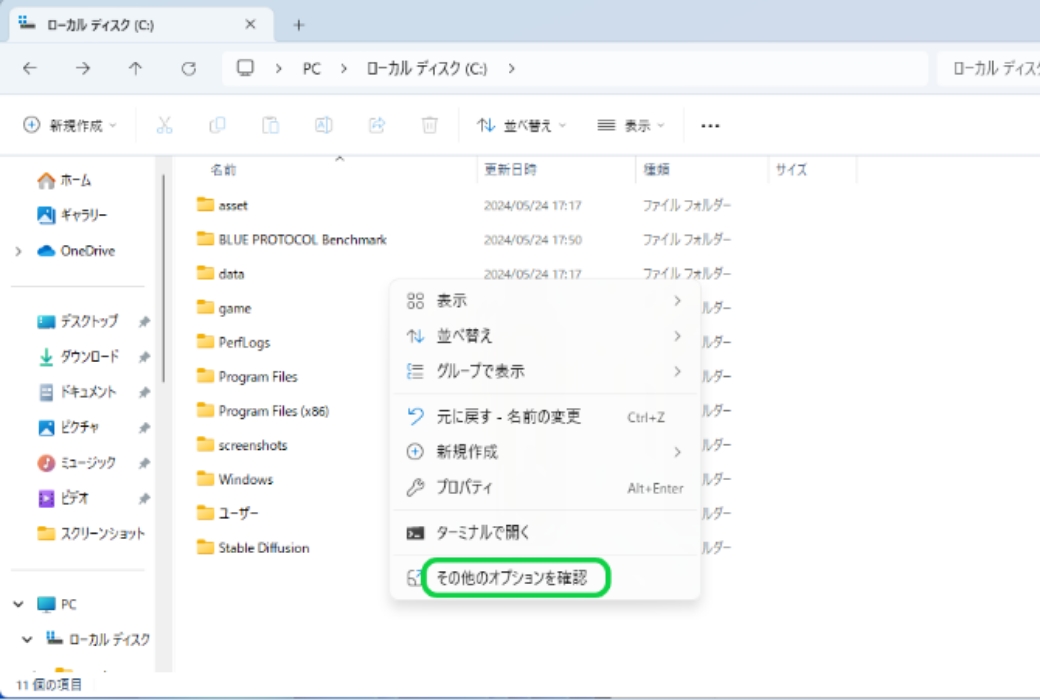
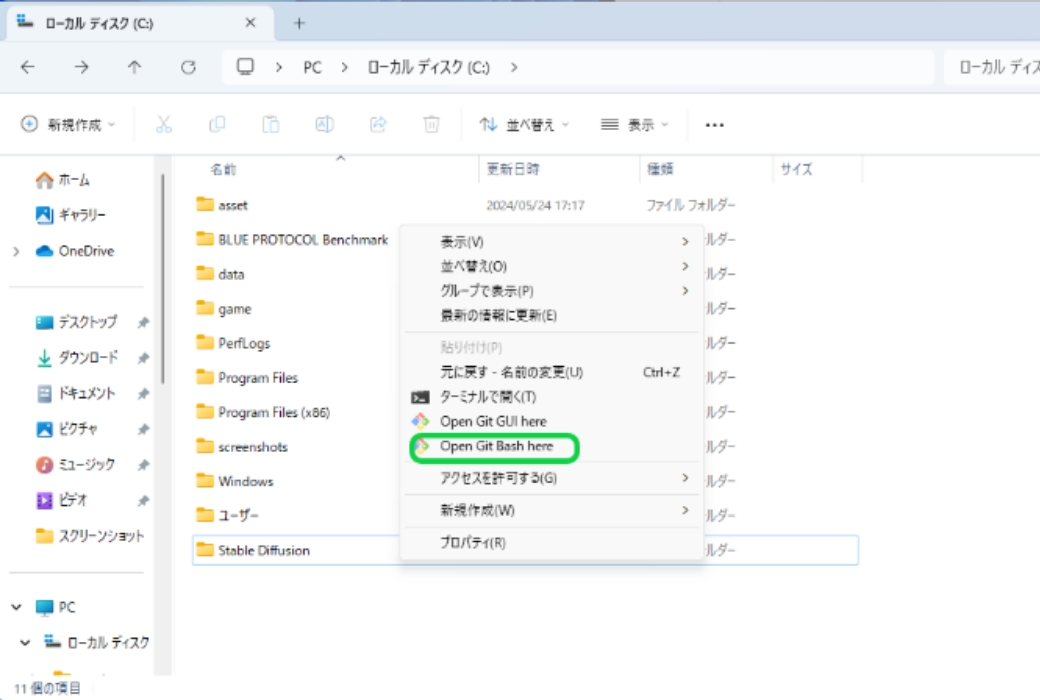
-
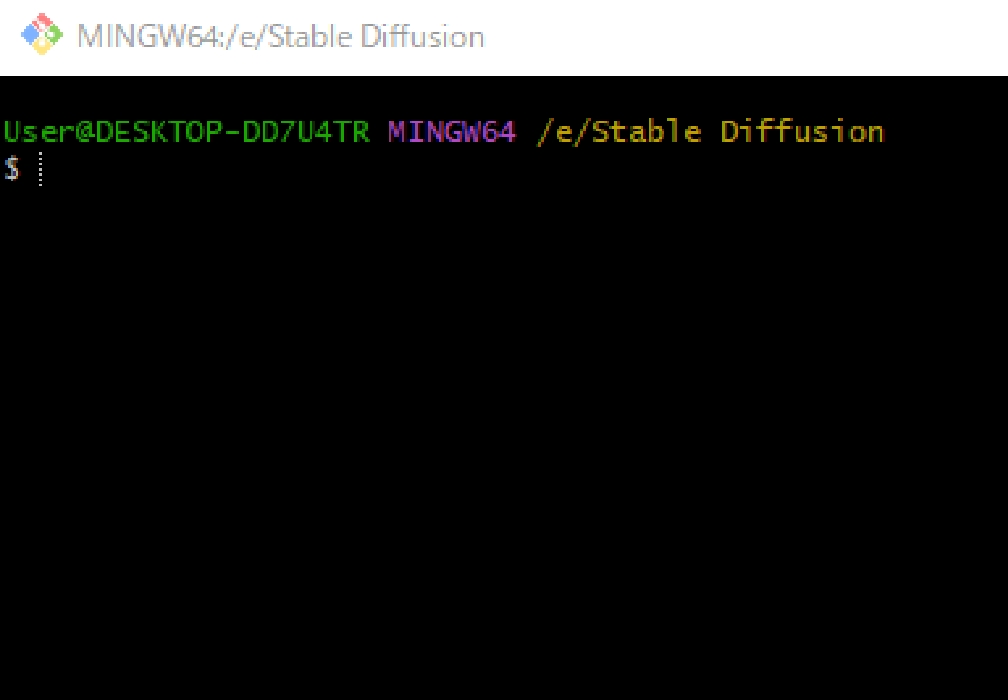
コマンドプロンプトが開くので、以下のコマンドを実行します。 git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git 右クリック→「paste」で貼り付けが可能です。コマンドが止まったらインストール完了です。
-
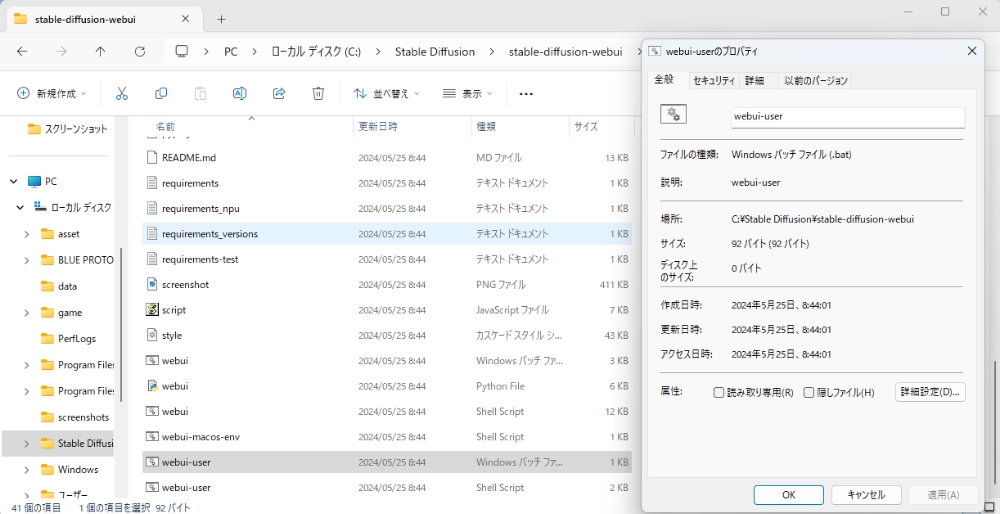
Stable Diffusionを利用する際は、作成したフォルダ→「stable-diffusion-webui」→下から2番目の「webui-user(batファイル)」をクリックしてコマンドを実行させます。
-
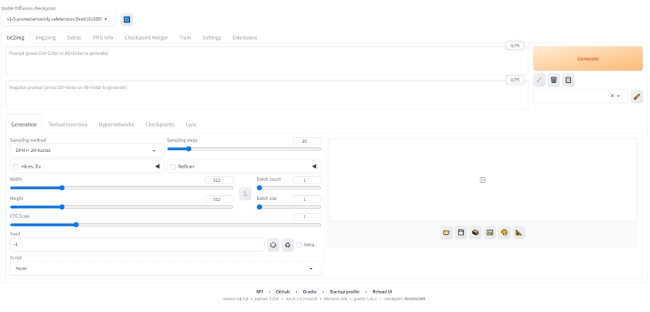
初回はコマンドが完了するまで10分以上時間がかかりますが、完了するとブラウザでStable Diffusionが自動で起動します。 自動で起動しない場合は「http://127.0.0.1:7860/」のURLから開くことも可能です。

以上が「AUTOMATIC 1111」を利用したStable Diffusion導入手順です。ちなみにコマンドプロントを閉じてしまうと機能停止してしまうので、起動後は最小化しておくのがおすすめです。
またStable Diffusionを取り巻く環境は、日々アップデートが行われています。新しいバージョンを導入することで利便性が高まりますが、逆に互換性が失われることで利用できなくなる要素が出ることもあるので注意が必要です。
またStable Diffusionを取り巻く環境は、日々アップデートが行われています。新しいバージョンを導入することで利便性が高まりますが、逆に互換性が失われることで利用できなくなる要素が出ることもあるので注意が必要です。
Stable Diffusion web UI の
メイン画面について
メイン画面について
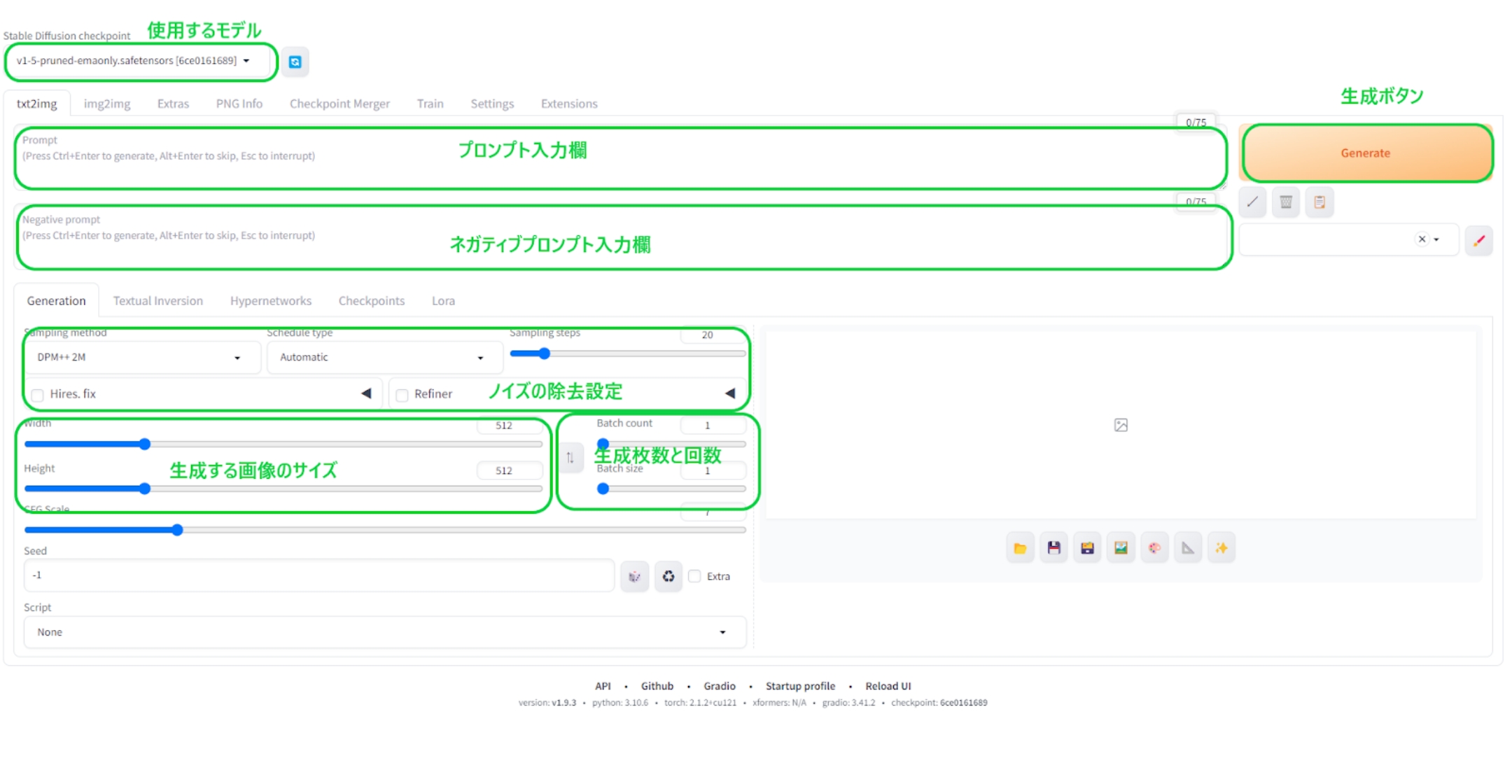
Stable Diffusion web UI(Version: v1.9.3)のメイン画面の各項目ですが、メインで使用する項目は以下の6つです。
生成する画像のサイズ、および生成枚数と回数によってGPU性能によって生成完了までの速度が変わります。この辺の条件については、後述の負荷テストにて触れたいと思います。
ノイズの除去設定は、不鮮明さや乱れといったノイズ要素の修正方法や回数を左右します。回数が多くなるということは、それだけ試行回数が増えるため生成速度は遅くなります。
極端に大きな画像サイズを生成すると、VRAM容量不足となりエラーが発生しやすくなります。大きな画像を描くためのキャンバスや作業スペースに相当するのがVRAMなので、描画しきれなくなるわけです。
一応メインメモリも使用することで、エラーを回避することもできるのですが、GPUから物理的に遠いメインメモリを使うと生成速度は明らかに遅くなります。この点においてVRAM容量12GBモデルが多いRTX4070シリーズの中で、唯一16GBのVRAMを持つRTX4070Ti SUPERは生成AI用途に適していると言えます。
ノイズの除去設定は、不鮮明さや乱れといったノイズ要素の修正方法や回数を左右します。回数が多くなるということは、それだけ試行回数が増えるため生成速度は遅くなります。
極端に大きな画像サイズを生成すると、VRAM容量不足となりエラーが発生しやすくなります。大きな画像を描くためのキャンバスや作業スペースに相当するのがVRAMなので、描画しきれなくなるわけです。
一応メインメモリも使用することで、エラーを回避することもできるのですが、GPUから物理的に遠いメインメモリを使うと生成速度は明らかに遅くなります。この点においてVRAM容量12GBモデルが多いRTX4070シリーズの中で、唯一16GBのVRAMを持つRTX4070Ti SUPERは生成AI用途に適していると言えます。
Stable Diffusion を
使い易くする
使い易くする
Stable Diffusionのローカル環境への導入について解説しましたが、まだまだ使用する上での課題があります。
まず言語が全て英語表記であるため、英語に疎い人にとっては使い難いです。ネット上で検索する際には日本語でも各種用語が出てくるので、操作画面に日本語と英語が併記されていた方が分かり易くなります。
まず言語が全て英語表記であるため、英語に疎い人にとっては使い難いです。ネット上で検索する際には日本語でも各種用語が出てくるので、操作画面に日本語と英語が併記されていた方が分かり易くなります。
日英併記化
-
まず①のExtensionsタブを選択し、②のAvailableをクリックします。
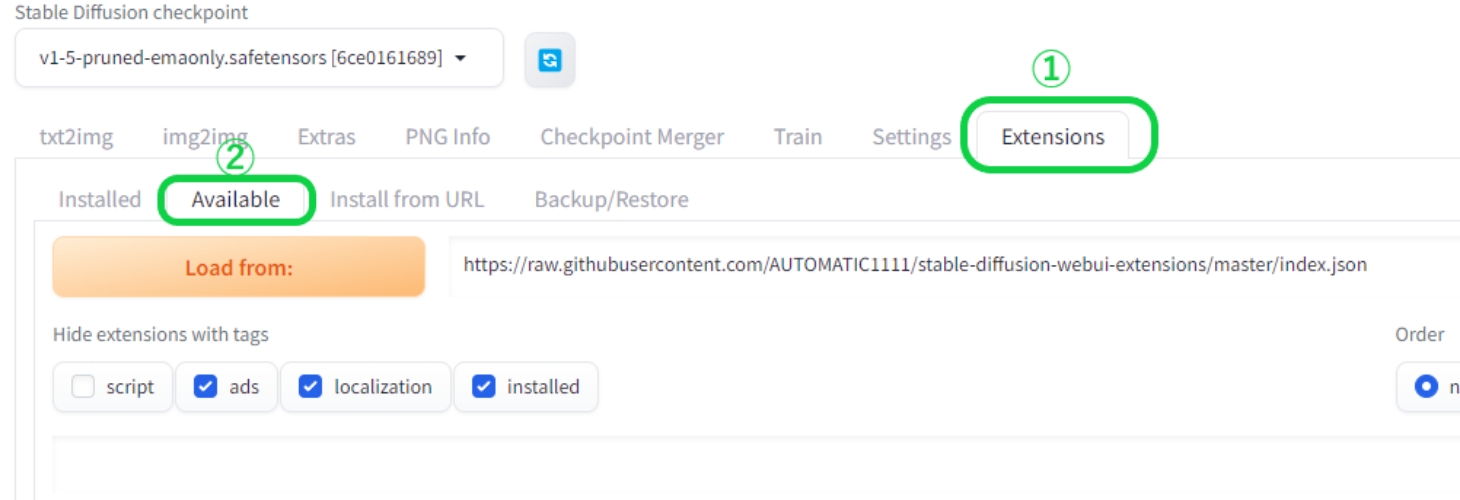
-
次にHide extensions with tagsにある③のlocalizationのチェックを外し、それ以外の項目にチェックを付けたら、④のLoad fromをクリックします。
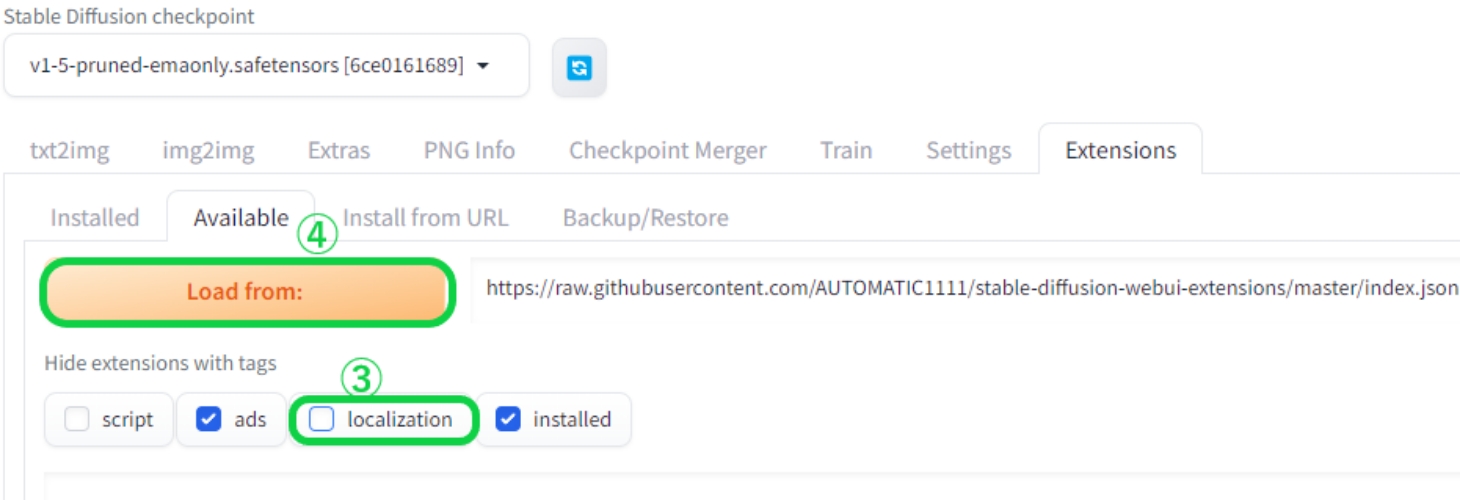
-
すると各種言語リストが出てきますので、「ja_JP Localization」の項目のInstallをクリックします。
Ctrl+Fキーを押せばページ内の検索バーが出ますので、それを利用すると一覧から探すのが容易となります。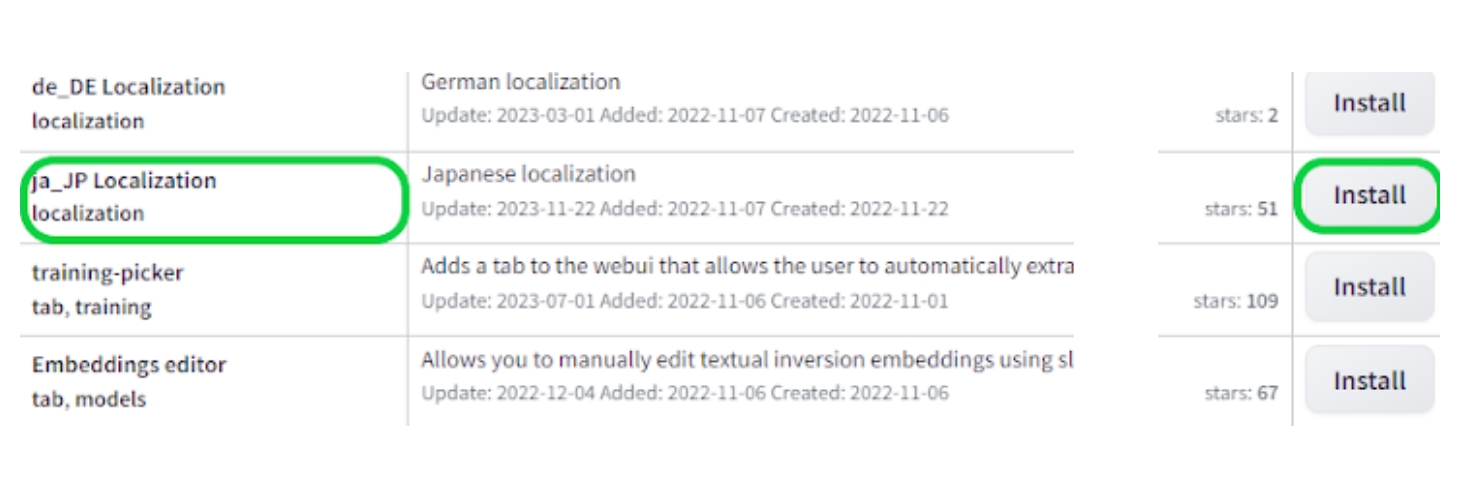
-
インストール後、⑤のSettingsタブ、もしくは検索バーより「Localization」より検索し、Localization (requires restart)の項目を探し、⑥のドロップダウンリストからja-JPがあることを確認し、確認後はNoneに戻します。
Ja-JPが出てこない場合は、右にあるアイコンを押してリロードしてみてください。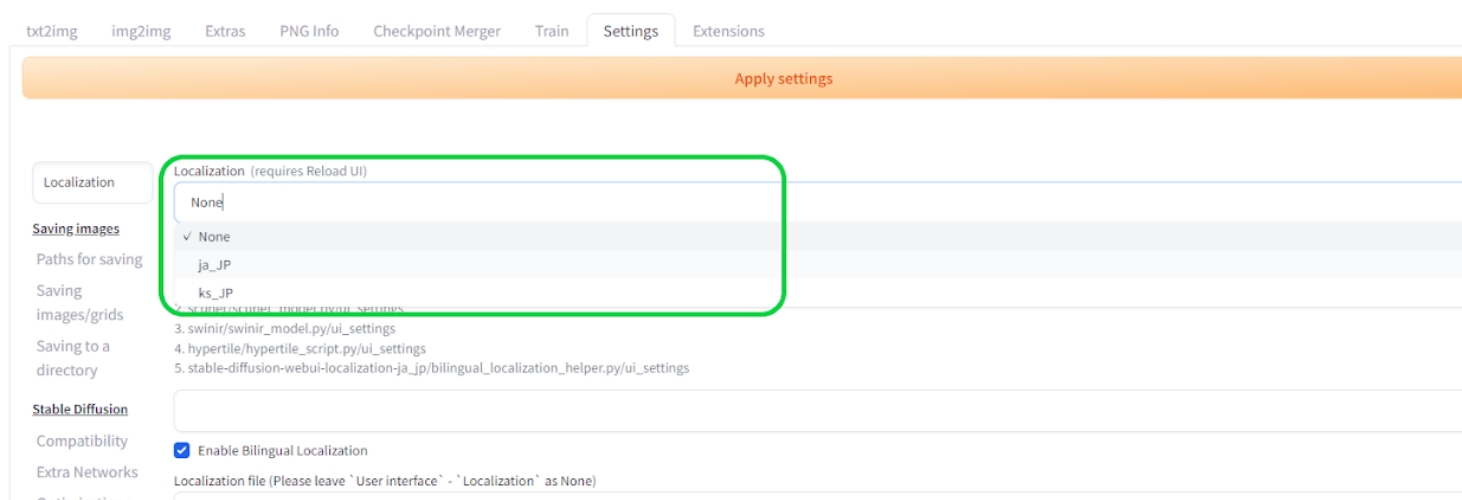
-
最後にSettings - Bilingual Localizationパネルから、⑦で「ja_JP」を選択し、⑧のApply setting、⑨のReload UIの順番でクリックすれば日英併記となります。
上手く併記されていない場合は
・ユーザーインターフェースの言語設定
(Localization)がNone
・Bilingual Localizationの言語設定がja_JP
になっているか確認してみてください。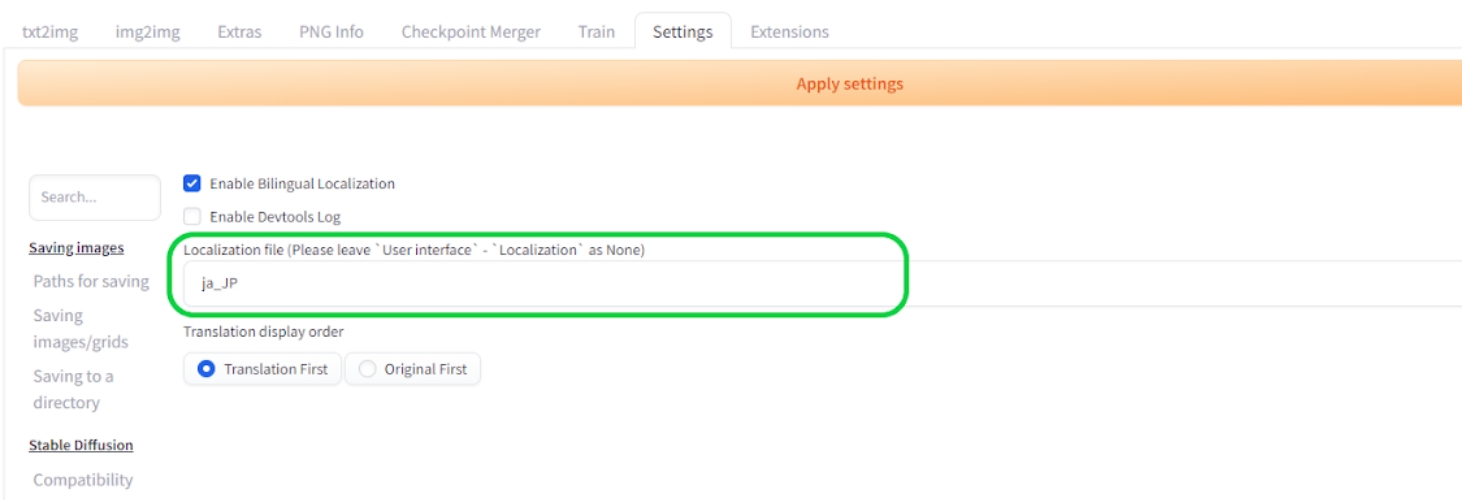
Stable Diffusion で画像生成を始めましょう
日本語併記化によって使い易くなり、画像生成ができる環境となってきました。
ただこの状態から理想とする画像を生成するには、基礎データとなる「モデル」が不足しているので、思ったような画風などが得られないことになります。
そこで事前準備としてモデルの導入方法、そこからプロンプトによる生成、LoRAも活用した応用的な使い方まで紹介したいと思います。
ただこの状態から理想とする画像を生成するには、基礎データとなる「モデル」が不足しているので、思ったような画風などが得られないことになります。
そこで事前準備としてモデルの導入方法、そこからプロンプトによる生成、LoRAも活用した応用的な使い方まで紹介したいと思います。
モデルを導入する方法
Stable Diffusionで使用できるモデルなどを配布しているサイトはいくつかありますが、「Civitai」からモデルを探していこうと思います。
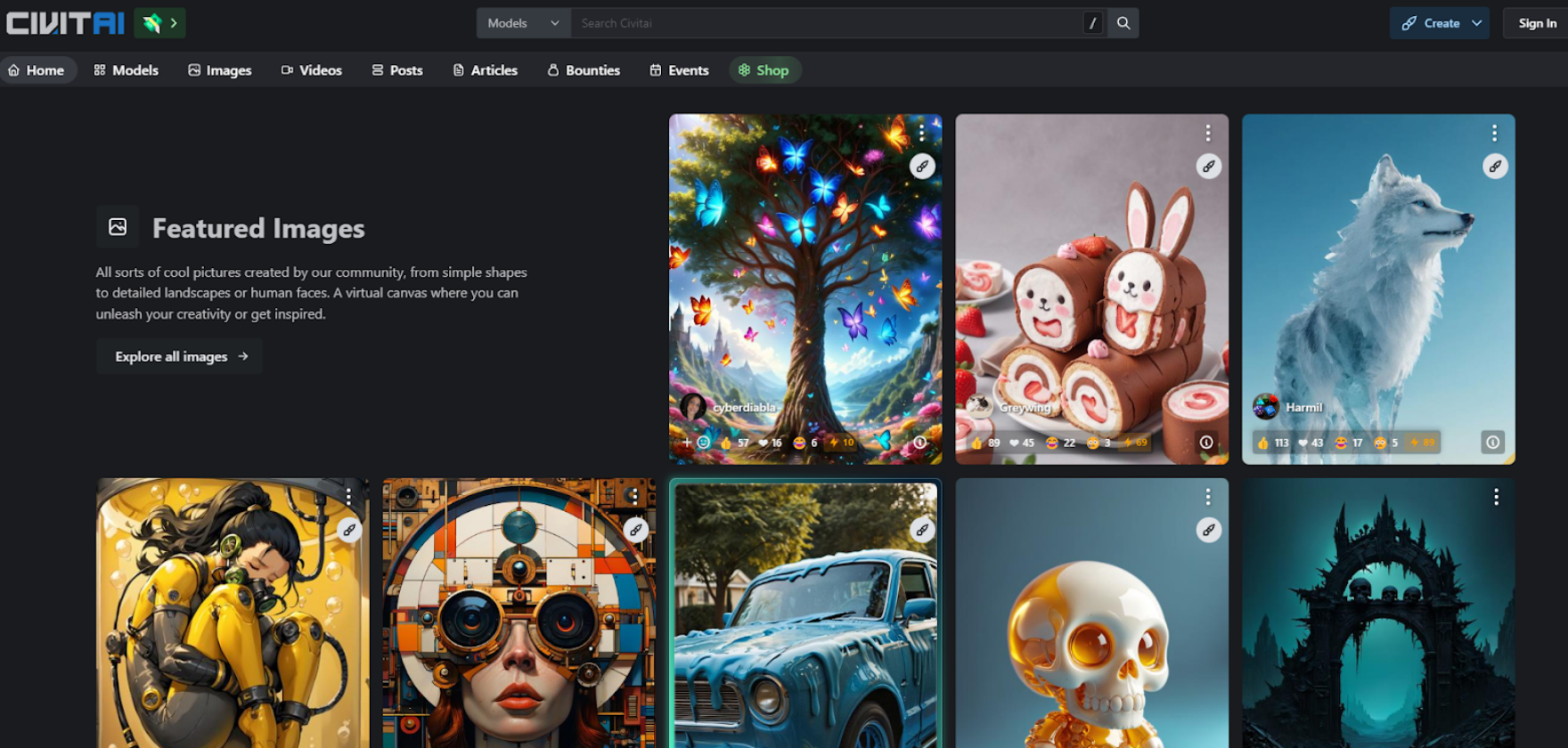
今回は「猫」の画像をメインで生成したいのですが、猫の画像と言っても写実、イラスト、アニメ調など様々な画風が考えられます。なので実際に出力したい画像の特徴を踏まえて、Civitaiのイメージ検索機能にて「cat」と入力し、ギャラリーにある猫の画像から気に入ったものを選びます。
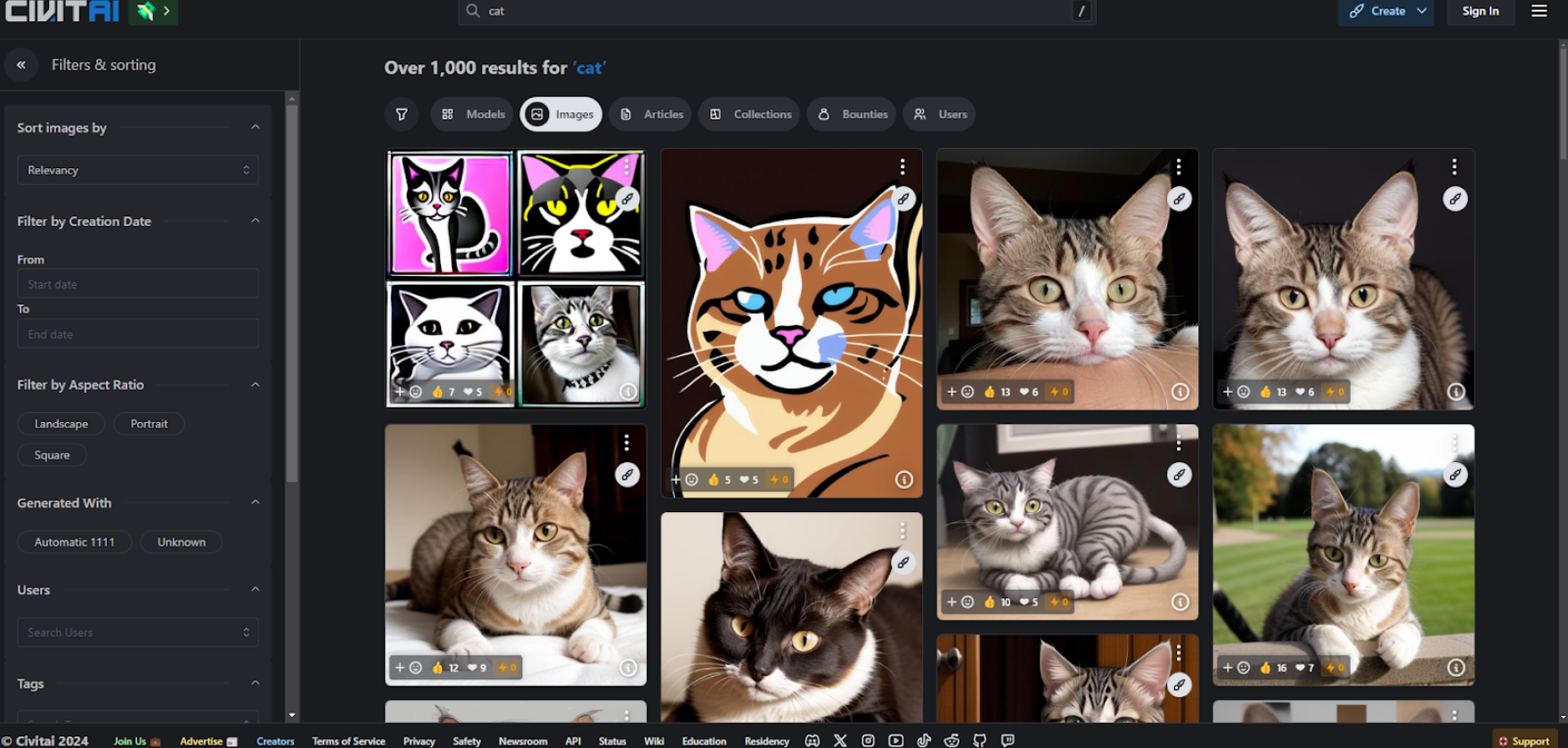
こちらの画像に使われているモデルを使用したいと思います。「ANINDE mix」がモデルとなっていますので、こちらのモデルのダウンロードページに飛びます。
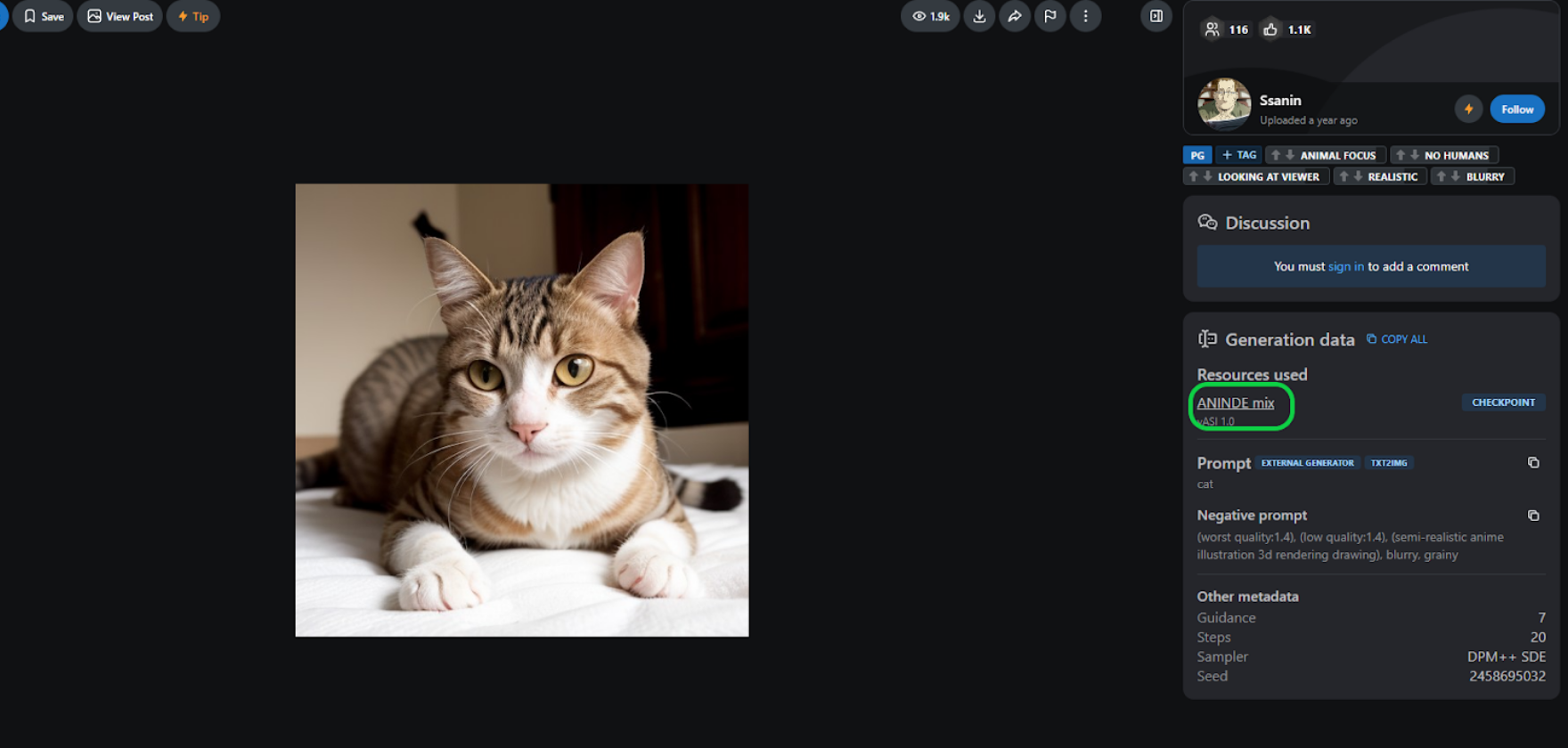
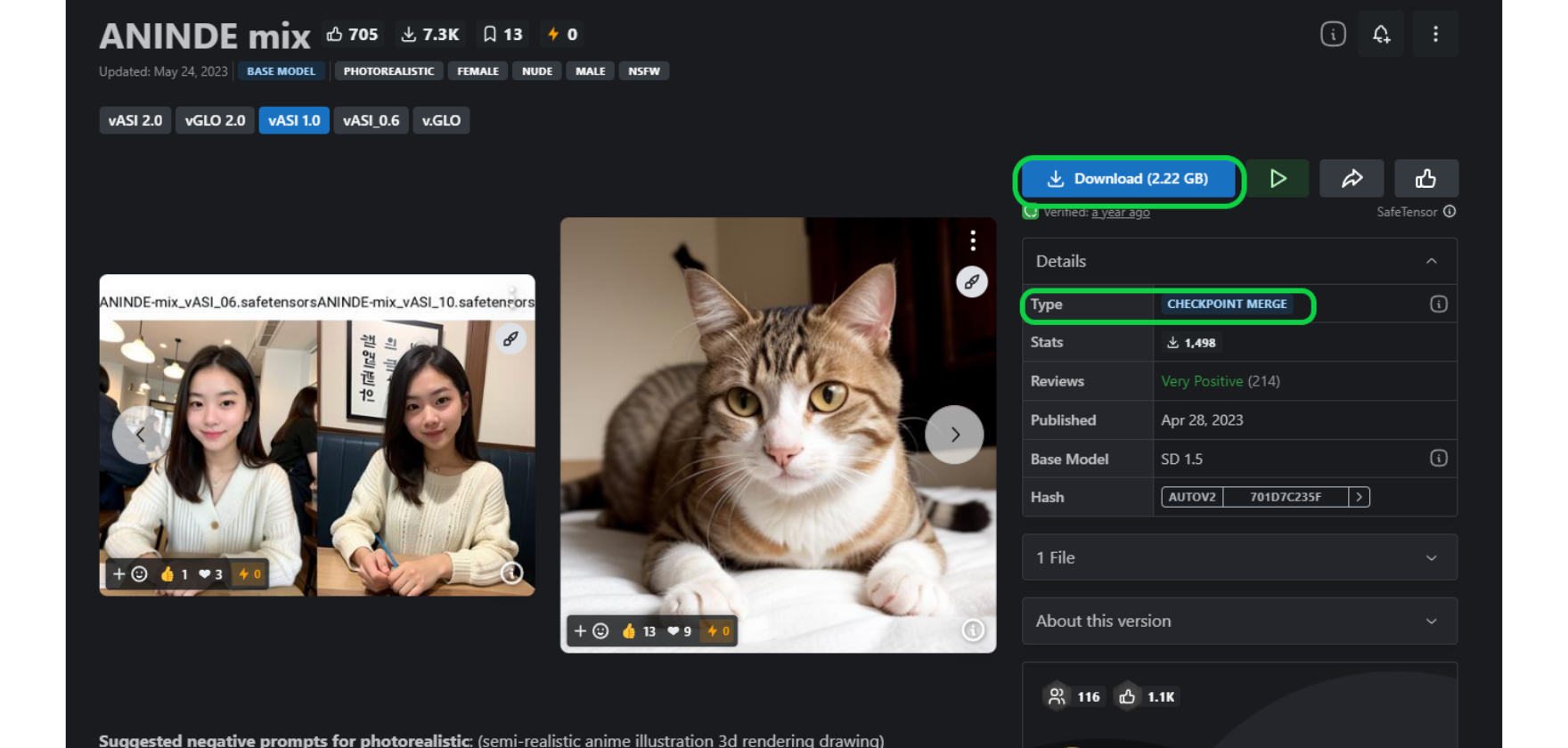
モデルのダウンロードページにてダウンロードを行います。
モデルを導入する上で気を付けておきたいのが、そのタイプ。
「チェックポイント」「LoRA」など様々な種類がありますが、大まかな画風を決めるのがチェックポイント。LoRAはアクセサリーや装飾等を付与する追加学習データになります。
モデルを導入する上で気を付けておきたいのが、そのタイプ。
「チェックポイント」「LoRA」など様々な種類がありますが、大まかな画風を決めるのがチェックポイント。LoRAはアクセサリーや装飾等を付与する追加学習データになります。
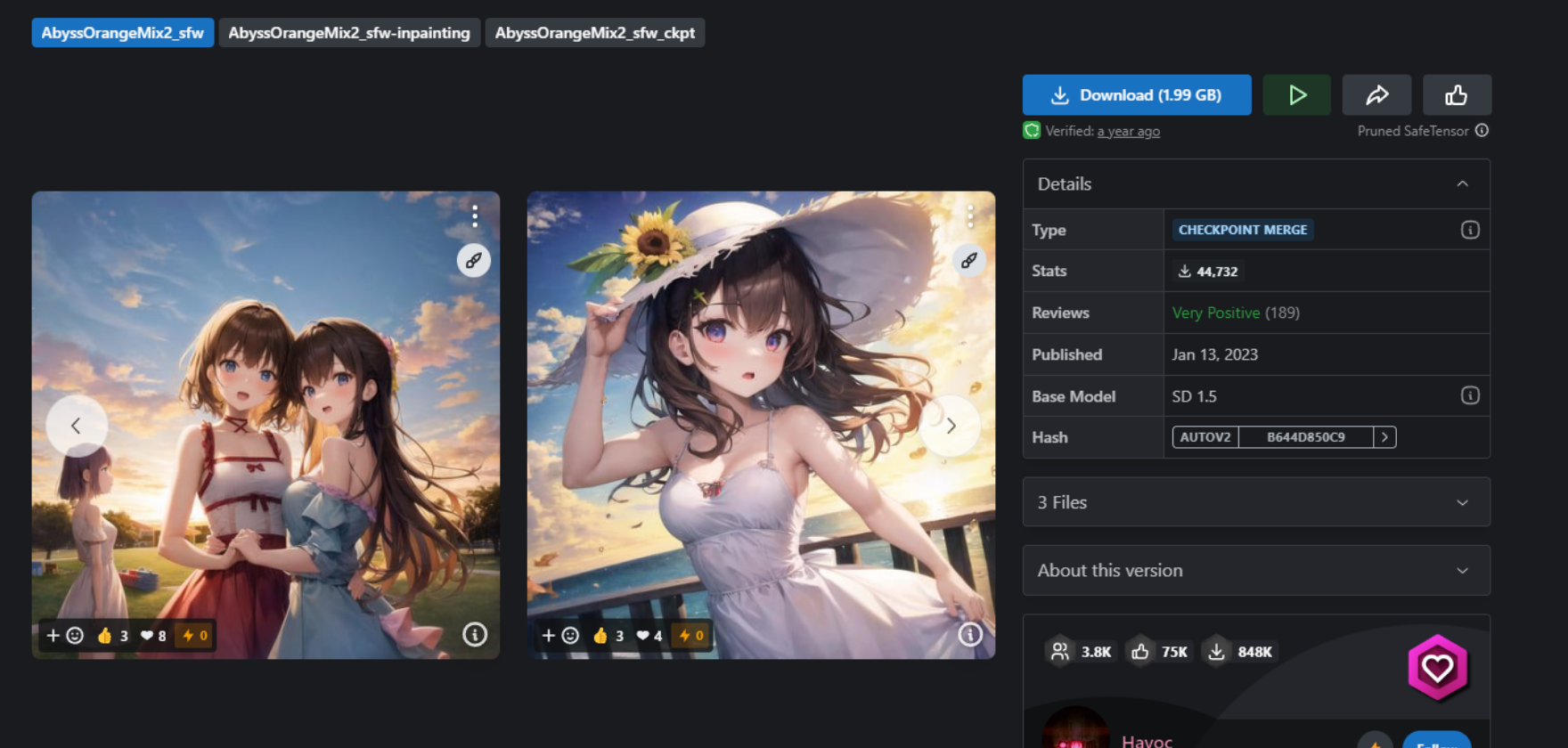
モデルによる画風などの変化なども確認したいので、アニメ・イラスト調のモデル
「AbyssOrangeMix2 - SFW/Soft NSFW」を導入してみましょう。
「AbyssOrangeMix2 - SFW/Soft NSFW」を導入してみましょう。
またアニメやイラスト系はLoRAによる変化も確認しやすいので、アニメ系のLORAも導入します。
それぞれダウンロードしたモデルなどのデータの格納先ですが、チェックポイントとなっているモデルは
「stable-diffusion-webui→modeles→Stable-diffusion」へ、LoRAは
stable-diffusion-webui→modeles→Lora」へと格納します。
データを格納し終えたら、既に起動しているStable Diffusion内でのリロード、もしくは再起動して読み込みを行います。
それぞれダウンロードしたモデルなどのデータの格納先ですが、チェックポイントとなっているモデルは
「stable-diffusion-webui→modeles→Stable-diffusion」へ、LoRAは
stable-diffusion-webui→modeles→Lora」へと格納します。
データを格納し終えたら、既に起動しているStable Diffusion内でのリロード、もしくは再起動して読み込みを行います。
基本編 画像を生成してみる
画像生成にあたって、プロンプトに画像の要素を決める英単語を打ち込むのが基本的な使い方となります。生成時のプロンプトのコツとしては
入力は英単語
単語の順番に気を付ける
単語と単語の間には「カンマ(, )+半角スペース」を入れる
排除したい要素=ネガティブプロンプトを入力する
と言った事が挙げられます。
ただ最初はプロンプト、特にネガティブプロンプトに入れるべき要素が分からないと思うので、コピペをして生成すること自体に慣れるのが良いと思います。
入力は英単語
単語の順番に気を付ける
単語と単語の間には「カンマ(, )+半角スペース」を入れる
排除したい要素=ネガティブプロンプトを入力する
と言った事が挙げられます。
ただ最初はプロンプト、特にネガティブプロンプトに入れるべき要素が分からないと思うので、コピペをして生成すること自体に慣れるのが良いと思います。

まずは見本にする猫の画像を、自分のPC上で再生成を行います。
ギャラリーからGeneration dataを参照しコピーします。同じものを生成する場合は「COPY ALL」をクリックすることで、一括でデータコピーできます。
ギャラリーからGeneration dataを参照しコピーします。同じものを生成する場合は「COPY ALL」をクリックすることで、一括でデータコピーできます。

コピーしたデータをStable Diffusion上で反映させるには
1.コピーしたデータをプロンプト欄にペースト入力
2.生成ボタン左下の矢印ボタンをクリックし、コピーデータの再配置
1.コピーしたデータをプロンプト欄にペースト入力
2.生成ボタン左下の矢印ボタンをクリックし、コピーデータの再配置

以上を行ってから、生成開始すると…
この様に同じような画像を生成できます。本来なら完全に一致するはずなのですが、Stable Diffusionのバージョンアップなどにより、全ての情報が反映されないようになったので、再現性が低くなっています。
この様に同じような画像を生成できます。本来なら完全に一致するはずなのですが、Stable Diffusionのバージョンアップなどにより、全ての情報が反映されないようになったので、再現性が低くなっています。

次に同じプロンプトを使用しつつ、モデルを「AbyssOrangeMix2 - SFW/Soft NSFW」に変更してみると…
この様に解釈違いも発生します。
これはモデルがプロンプトの「cat(猫)」の意味をどう解釈しているか?によって変わるものとなります。
モデルによっては「猫の事前情報がない」ために、猫要素ゼロ、ノイズだらけの画像が生成されることもあります。人で言えば未知の存在を絵で表現し難いのと同じです。
この様に解釈違いも発生します。
これはモデルがプロンプトの「cat(猫)」の意味をどう解釈しているか?によって変わるものとなります。
モデルによっては「猫の事前情報がない」ために、猫要素ゼロ、ノイズだらけの画像が生成されることもあります。人で言えば未知の存在を絵で表現し難いのと同じです。

次に「AbyssOrangeMix2 - SFW/Soft NSFW」で同じプロンプトを使用しつつ、LoRAを適応させてみます。
LoRAを反映させるにはトリガーワードをプロンプロに入力するのですが、LoRAタブから使用したいLoRAを選んでクリックすると入力されます。
LoRAを反映させるにはトリガーワードをプロンプロに入力するのですが、LoRAタブから使用したいLoRAを選んでクリックすると入力されます。
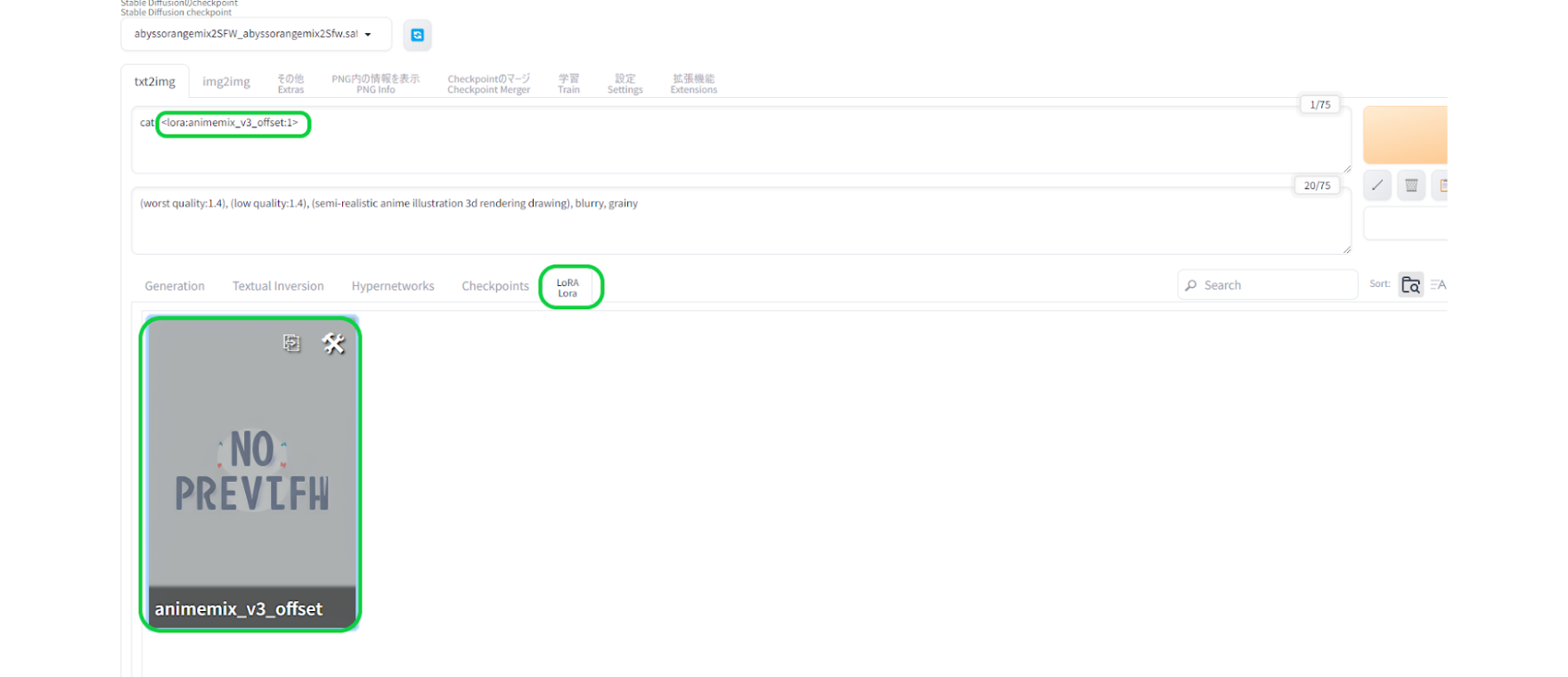
何枚か生成してみましたが、LoRAを適応させると猫を正しく認識し、なおかつアニメ調にするLoRAの影響が強く出ました。

元画像を参照して
別の画像を生成
別の画像を生成
基本的に生成される画像はランダム、いわゆるガチャ要素が含まれます。
生成された画像の中で出来の良い物が生まれる、あるいはCivitaiなどで良さそうな画像を見つけた場合、「この画像をベースにした、違う画風の画像を生成したい」「この絵の良い部分を継承したい」と思う事が出てくるかと思います。
そんな時に便利な「コントロールネット(Controlnet)」という拡張機能を、更なる応用編として紹介したいと思います。
生成された画像の中で出来の良い物が生まれる、あるいはCivitaiなどで良さそうな画像を見つけた場合、「この画像をベースにした、違う画風の画像を生成したい」「この絵の良い部分を継承したい」と思う事が出てくるかと思います。
そんな時に便利な「コントロールネット(Controlnet)」という拡張機能を、更なる応用編として紹介したいと思います。
準備編 コントロールネットの導入
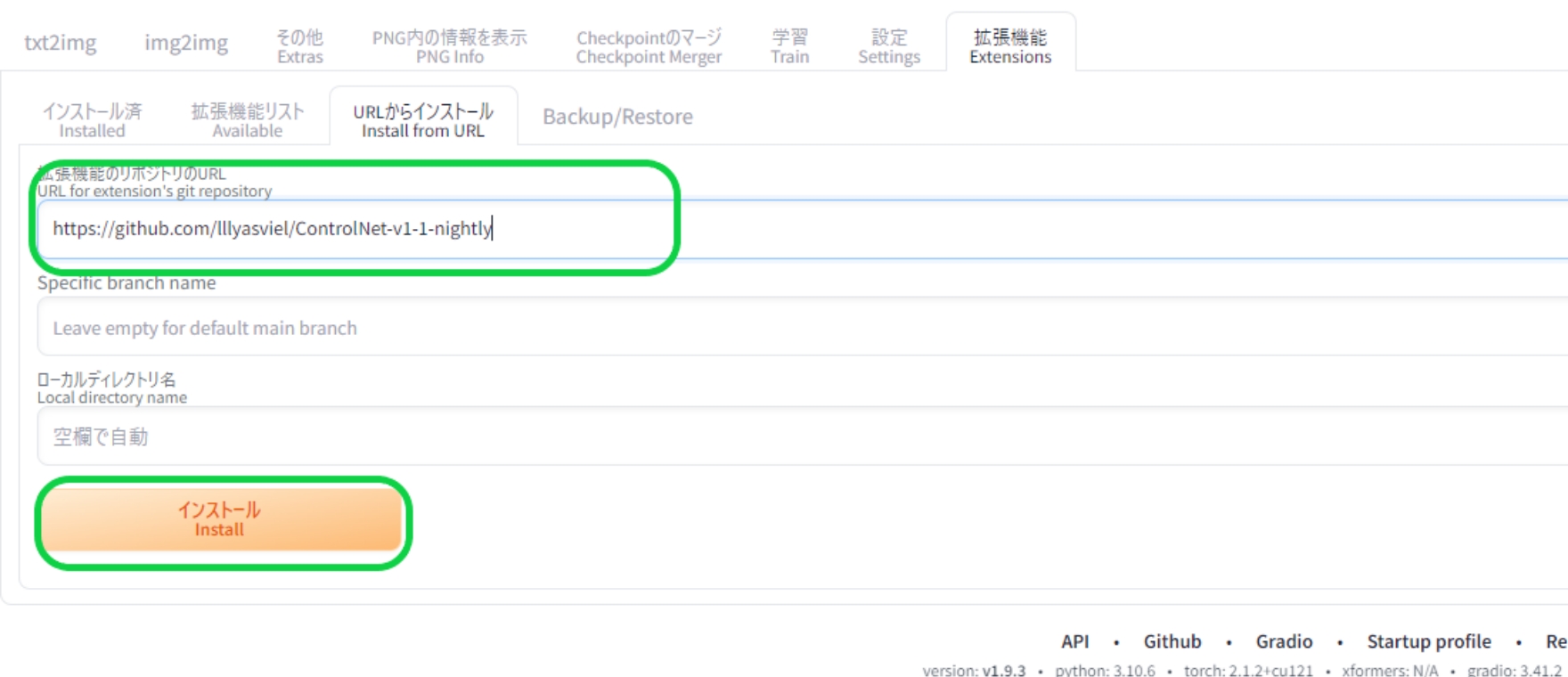
まずコントロールネット自体は拡張機能であるため、標準のStable Diffusionには備わっていません。そこでコントロールネットの導入作業が必要となります。
Extensionタブを開き、Install from URLから下記のURLを入力し、インストールします。
Extensionタブを開き、Install from URLから下記のURLを入力し、インストールします。
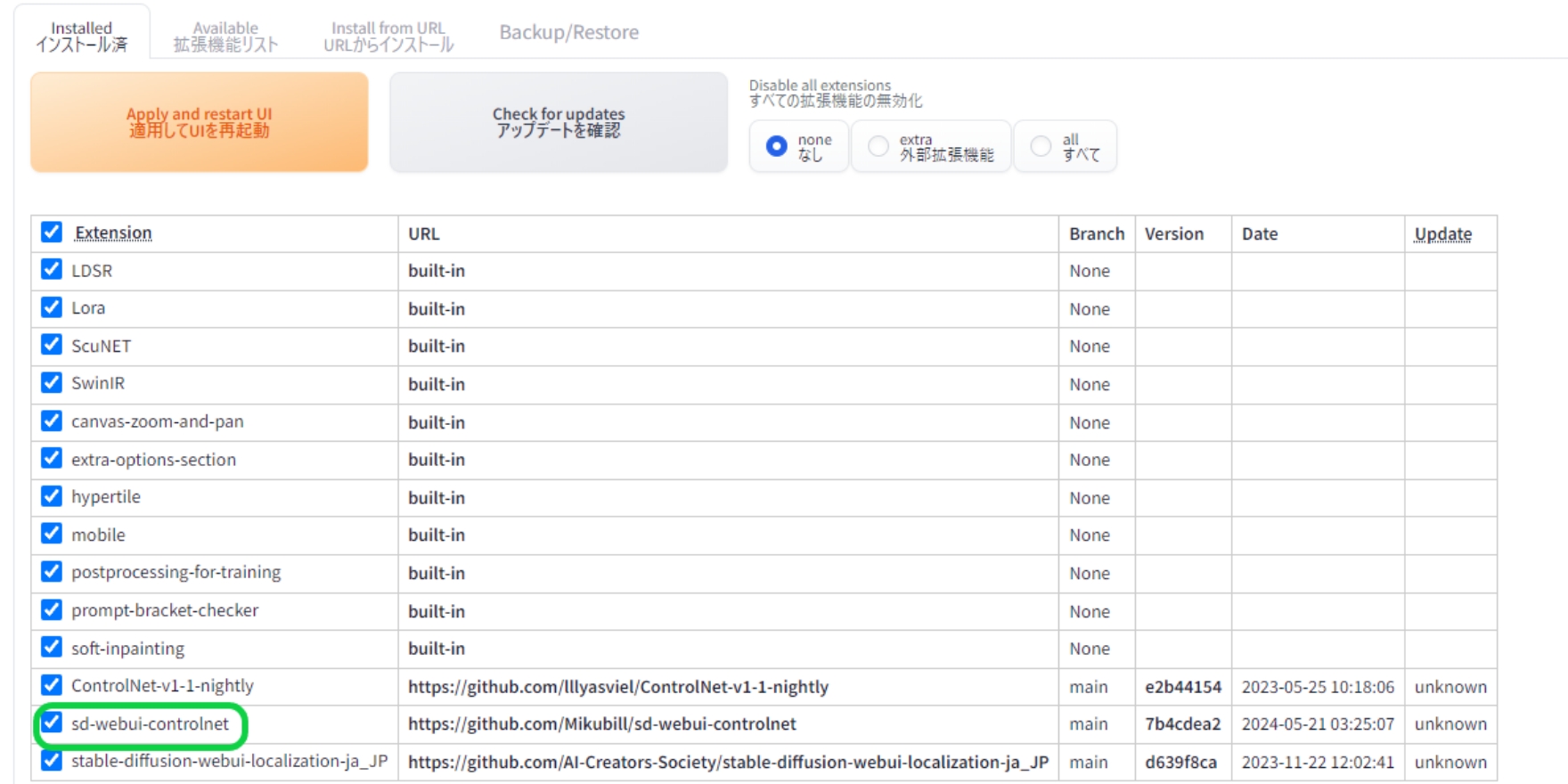
インストールが完了すると、installed内に「sd-webui-controlnet」と出てくるので、Apply and restat UIをクリックして再起動します。
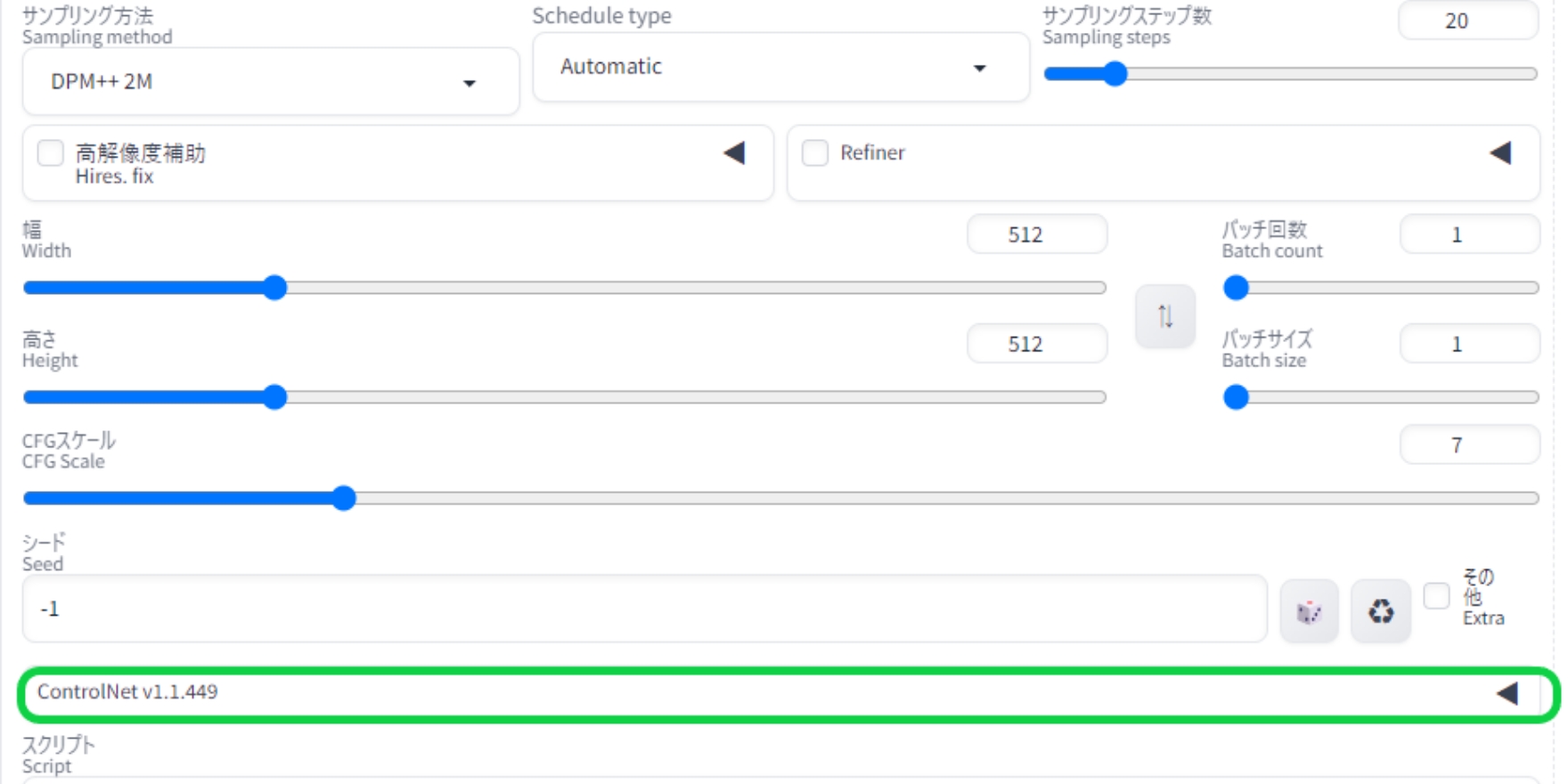
再起動後、Stable Diffusionメイン画面のシード値の下部にコントロールネットのメニューが出ていれば、拡張機能としてのコントロールネットは導入完了となります。
もしコントロールネットが出てこない場合は、下記のURLで同様の手順を踏んでインストールを試みてください。
ただこのままではコントロールネットの機能は使えないので、コントロールネット専用モデルデータを続けて導入していきます。
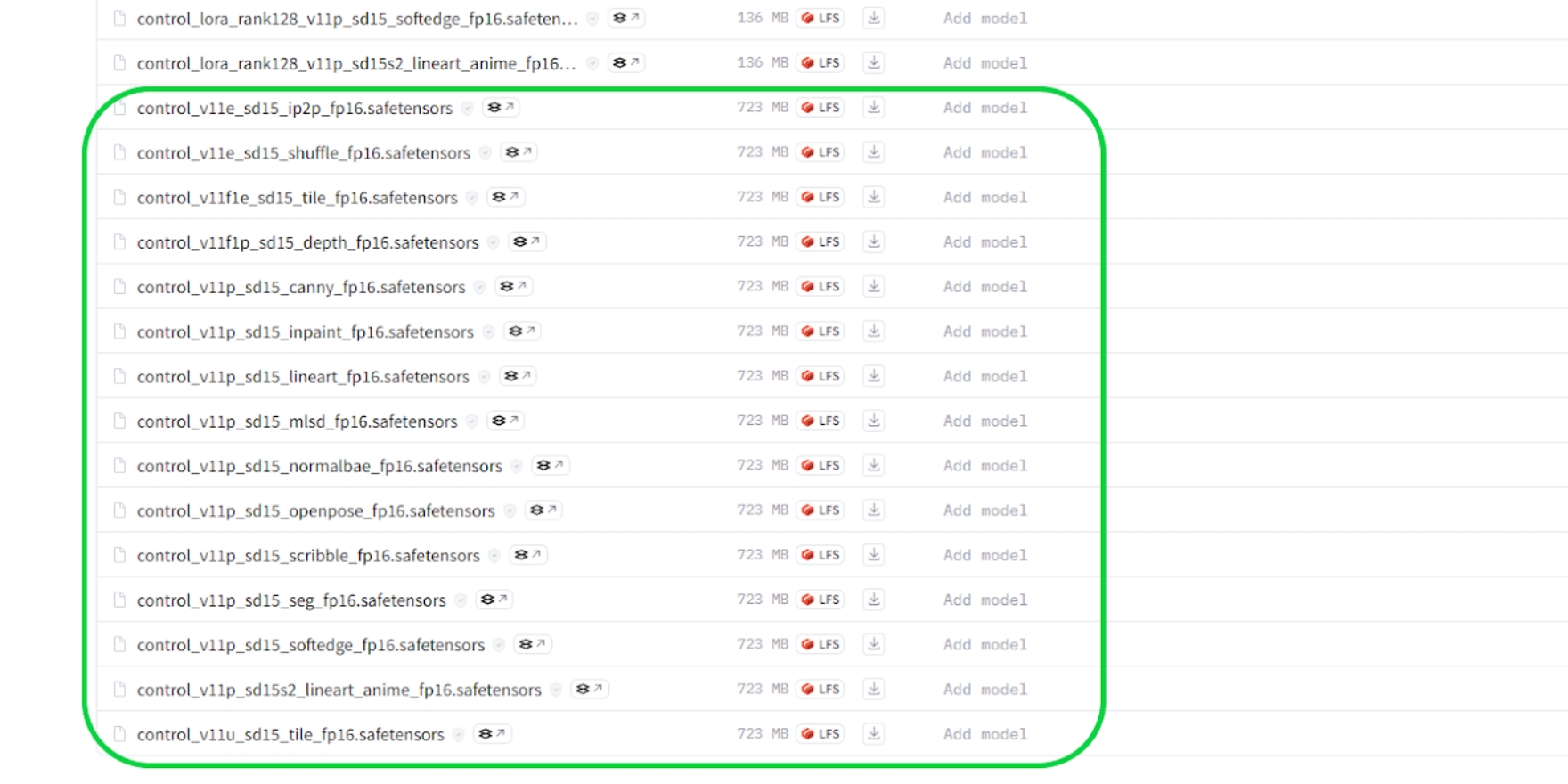
下記のHugging Face のURLにアクセスし、名称「control_v11p_sd15_〇〇〇_fp16.safetensors」となっている物をダウンロードします。
モデルのダウンロード完了後、『stable-diffusion-webui』→『extensions』→『sd-webui-controlnet』→『models』のフォルダ内にモデルを格納します。チェックポイントやLoRAの格納場所とは違うので、注意してください。
下記のHugging Face のURLにアクセスし、名称「control_v11p_sd15_〇〇〇_fp16.safetensors」となっている物をダウンロードします。
モデルのダウンロード完了後、『stable-diffusion-webui』→『extensions』→『sd-webui-controlnet』→『models』のフォルダ内にモデルを格納します。チェックポイントやLoRAの格納場所とは違うので、注意してください。
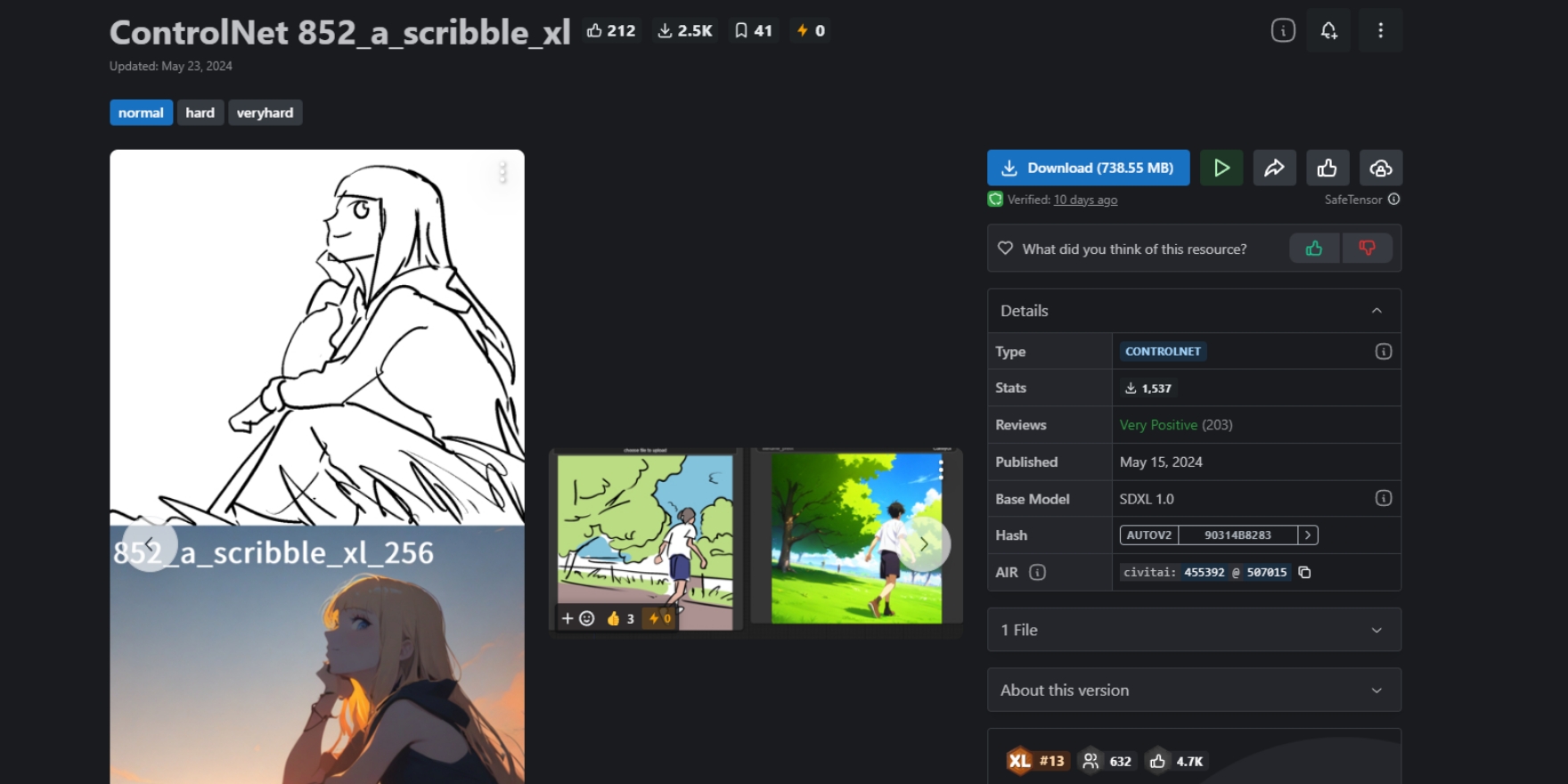
またCivitaiでもコントロールネットのモデルが配布されていますので、こちらを利用することもできます。ただし先に紹介したコントロールネット用モデルとは違い、ベースモデルの相性が存在します。
今回紹介する「ControlNet 852_a_scribble_xl」の場合には、SDXLのベースモデルに適した物となっていますので、同じSDXLのモデルと組み合わせないと上手く出力できないため、合わせて導入しましょう。
今回紹介する「ControlNet 852_a_scribble_xl」の場合には、SDXLのベースモデルに適した物となっていますので、同じSDXLのモデルと組み合わせないと上手く出力できないため、合わせて導入しましょう。
コントロールネットを使って
アニメ調の画像に編集
アニメ調の画像に編集
コントロールネットは参照元となる画像データから、新たな画像を生成することができます。コントロールネットのモデルとは、その手法の差になります。
代表的な物としては、画像から線画を抽出する「Canny」、人物のポーズを棒人間の形で抽出する「openpose」などの手法があります。その他にも手法はいくつもあるのですが、ここでは紹介しきれないので、簡単な手法を紹介します。
テストとして「先程生成した写実的な猫の画像を、アニメ風に」という作業を行います。
代表的な物としては、画像から線画を抽出する「Canny」、人物のポーズを棒人間の形で抽出する「openpose」などの手法があります。その他にも手法はいくつもあるのですが、ここでは紹介しきれないので、簡単な手法を紹介します。
テストとして「先程生成した写実的な猫の画像を、アニメ風に」という作業を行います。

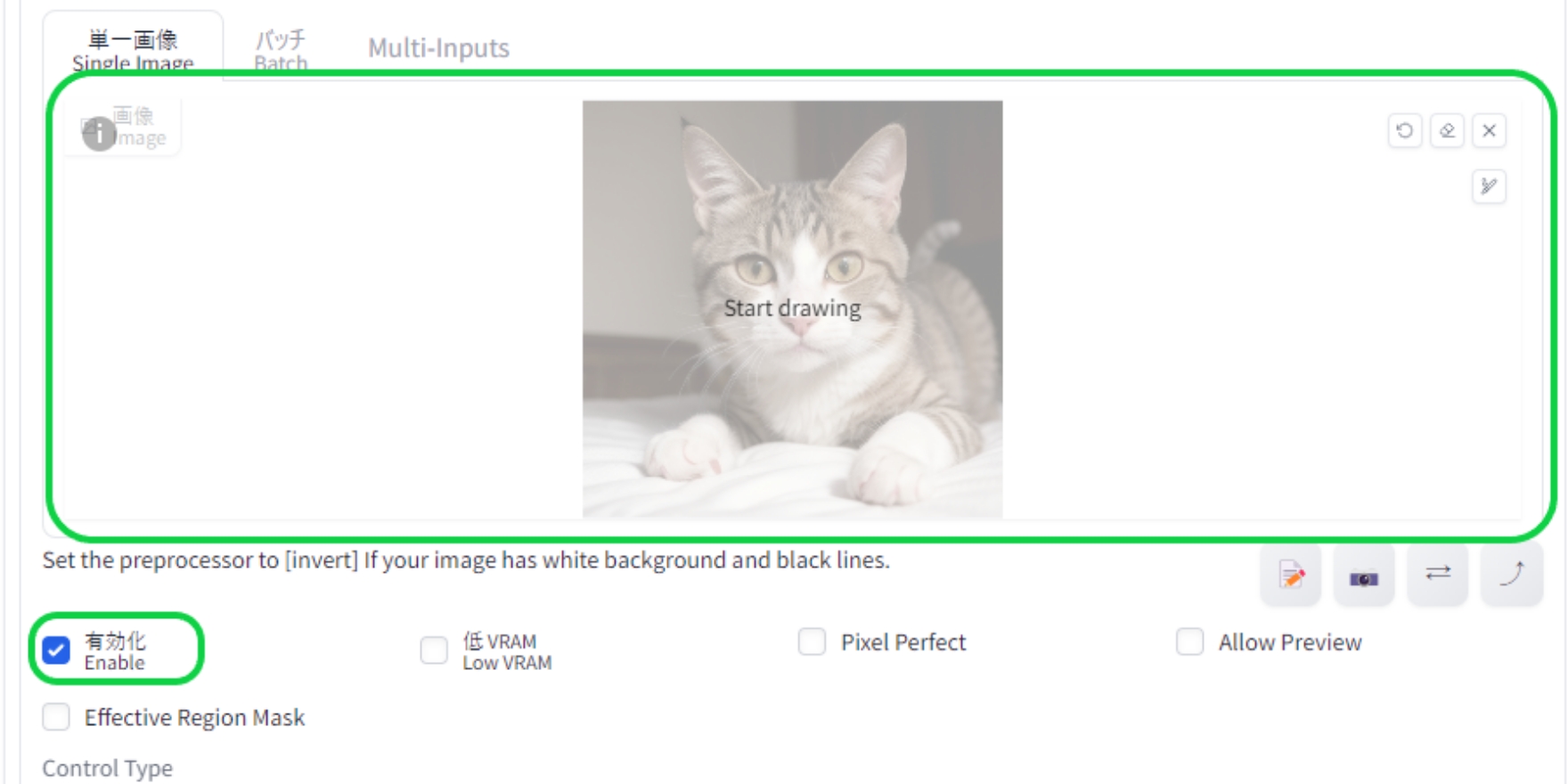
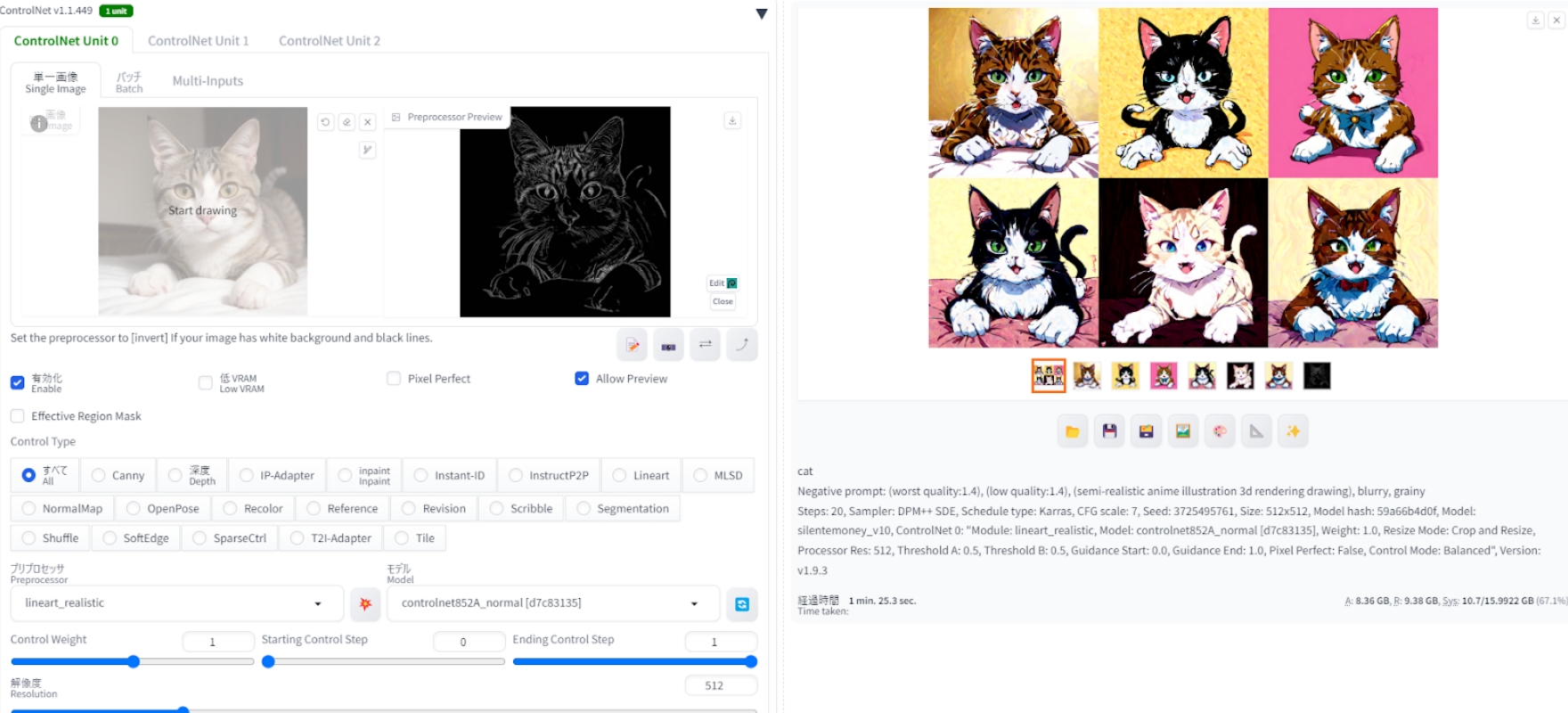
まずはコントロールネットメニューを開き、「Enable」にチェックを入れ有効化。そして「Sigle Image」の枠内に参照元となる画像をドロップします。
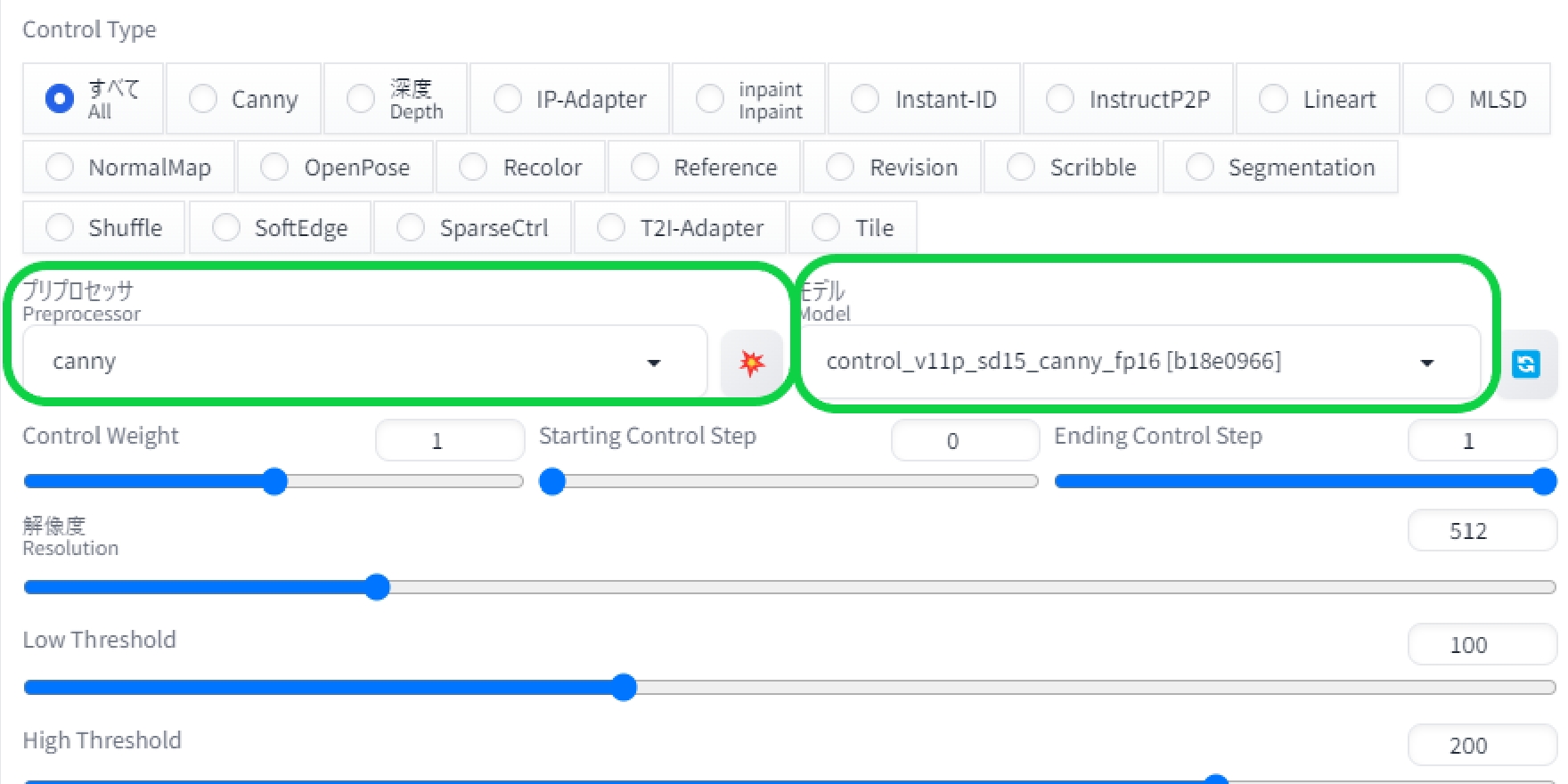
次に「Preprocessor」と「model」を選択します。
ここが画像データの抽出法を決める部分なのですが、今回は猫が対象となるため人物のポーズを参照するopenposeは不向き。線画を抽出するCannyなどが適しているでしょう。
Preprocessorは抽出方法の設定であり、今回のように生成前に参照したい画像データの抽出作業をしたい場合には設定する必要があります。選択メニュー横のアイコンを押すと、画像から抽出される線画などのデータを確認することもできます。
既に画像からデータを抽出し終えている場合にはnone=無しに。そしてコントロールネット内のモデルの項目より、抽出されているデータの参照方法を選択します。これでコントロールネット側の基本的な設定は完了です。
あとは画像生成時と同じ要領で、プロンプトなどを入力し、反映させたい画風を持ったモデルを適応させて生成を行います。
ここが画像データの抽出法を決める部分なのですが、今回は猫が対象となるため人物のポーズを参照するopenposeは不向き。線画を抽出するCannyなどが適しているでしょう。
Preprocessorは抽出方法の設定であり、今回のように生成前に参照したい画像データの抽出作業をしたい場合には設定する必要があります。選択メニュー横のアイコンを押すと、画像から抽出される線画などのデータを確認することもできます。
既に画像からデータを抽出し終えている場合にはnone=無しに。そしてコントロールネット内のモデルの項目より、抽出されているデータの参照方法を選択します。これでコントロールネット側の基本的な設定は完了です。
あとは画像生成時と同じ要領で、プロンプトなどを入力し、反映させたい画風を持ったモデルを適応させて生成を行います。
するとこのように構図などはそのままに、画風だけが変化します。猫の線画を取り込んでいることでポーズが固定化され、毛色などが変化するようになっています。

コントロールネットとSDXLのモデルを組み合わせるとこのような感じに。
基本的な構図などは参照していますが、プロンプトとモデルの影響が強め。ですが「写実的な猫の画像を、アニメ風に」という意味では成功しています。
基本的な構図などは参照していますが、プロンプトとモデルの影響が強め。ですが「写実的な猫の画像を、アニメ風に」という意味では成功しています。
EFFA E47IMでの
動作について
動作について
今回の検証用PCとして活用している「EFFA E47IM」。ゲーミングPCとして高い適性を持っていますが、ここではStable Diffusionでの生成時の挙動について述べたいと思います。
EFFA E47IM × Stable Diffusion 負荷テスト
画像生成においてはシード値が-1になっている場合、ランダムに生成されることになります。これが画像生成におけるガチャ要素となるわけですが、より多くの画像を短時間で生成できた方が効率的と言えます。
そこでStable Diffusionで512×512ピクセルの画像を合計6枚生成し、描き上がるまでにかかる時間、およびタスクマネージャー上でGPUのVRAM使用量などを確認する負荷テストを行います。
使用モデルは「AbyssOrangeMix2 - SFW/Soft NSFW」、プロンプトなどの生成データは引き続き「猫」の物を使用。コントロールネットおよびLoRAは無し。生成される結果は同じにしないと生成時間にブレが生じるので、シード値は固定とします。
そこでStable Diffusionで512×512ピクセルの画像を合計6枚生成し、描き上がるまでにかかる時間、およびタスクマネージャー上でGPUのVRAM使用量などを確認する負荷テストを行います。
使用モデルは「AbyssOrangeMix2 - SFW/Soft NSFW」、プロンプトなどの生成データは引き続き「猫」の物を使用。コントロールネットおよびLoRAは無し。生成される結果は同じにしないと生成時間にブレが生じるので、シード値は固定とします。

連続生成をする上で重要なのが、バッチ回数とバッチサイズの組み合わせです。回数は描き出し行う回数、バッチサイズは一度に広げられるキャンバスの数と考えてもらえば良いと思います。
描き出し回数重視で連続生成する場合、単純にGPUの処理能力が時間短縮に繋がります。一方バッチサイズは一度に広げられるキャンバスの枚数なので、VRAM容量が多いほど作業スペースが大きくて有利。そしてGPUは圧倒的な演算コア数によって成り立っているので、マルチタスク=並列処理がとても得意です。
以上の事から「VRAM容量の限界付近までキャンバス=バッチサイズを広げ、GPUの圧倒的なマルチタスク能力で描き上げる」というのが最も効率が良いと推測されます。
描き出し回数重視で連続生成する場合、単純にGPUの処理能力が時間短縮に繋がります。一方バッチサイズは一度に広げられるキャンバスの枚数なので、VRAM容量が多いほど作業スペースが大きくて有利。そしてGPUは圧倒的な演算コア数によって成り立っているので、マルチタスク=並列処理がとても得意です。
以上の事から「VRAM容量の限界付近までキャンバス=バッチサイズを広げ、GPUの圧倒的なマルチタスク能力で描き上げる」というのが最も効率が良いと推測されます。
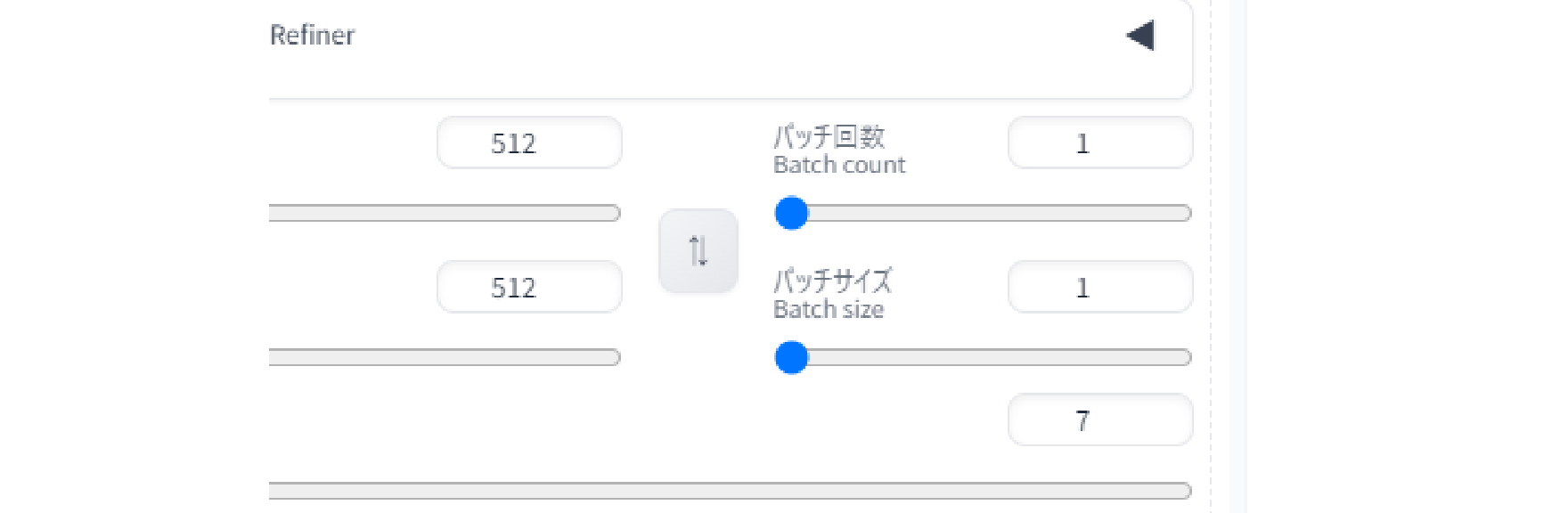
では本当にVRAM容量一杯までバッチサイズを使うと効率が良いのか?
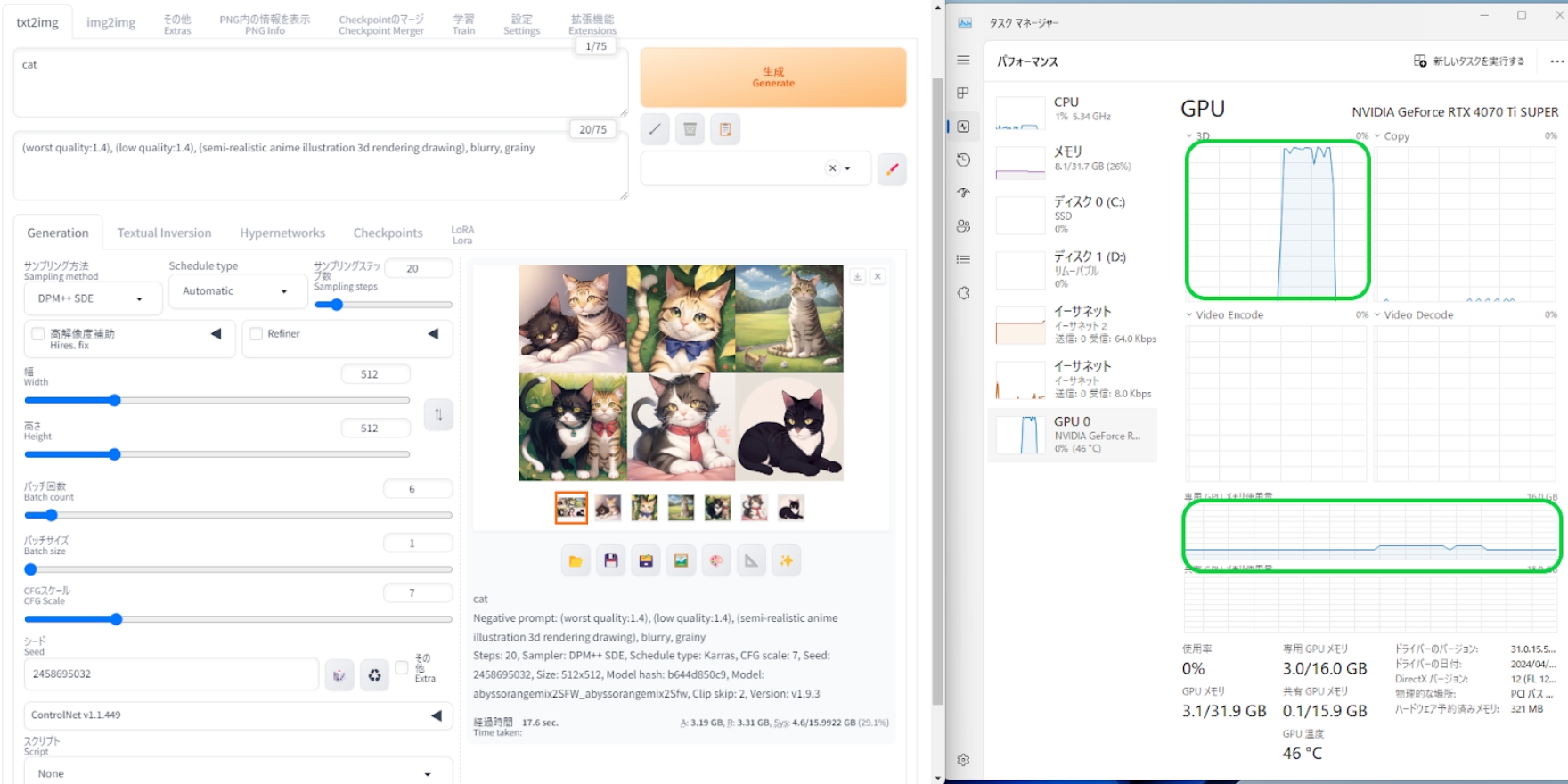
まずはバッチ回数6回での6枚連続生成。タスクマネージャー上のグラフで、生成中のGPU使用率とVRAM使用率も確認できますが、GPU使用率が100%近くありながらVRAM使用率はかなり低いです。
GPU的には1枚ずつ描き出していることになるので、作業スペースになるVRAMは1枚分になります。描き出し完了後のステータス表示を確認したところ、生成時間は17.6秒でした。
まずはバッチ回数6回での6枚連続生成。タスクマネージャー上のグラフで、生成中のGPU使用率とVRAM使用率も確認できますが、GPU使用率が100%近くありながらVRAM使用率はかなり低いです。
GPU的には1枚ずつ描き出していることになるので、作業スペースになるVRAMは1枚分になります。描き出し完了後のステータス表示を確認したところ、生成時間は17.6秒でした。
次にバッチサイズ6にして6枚同時生成。
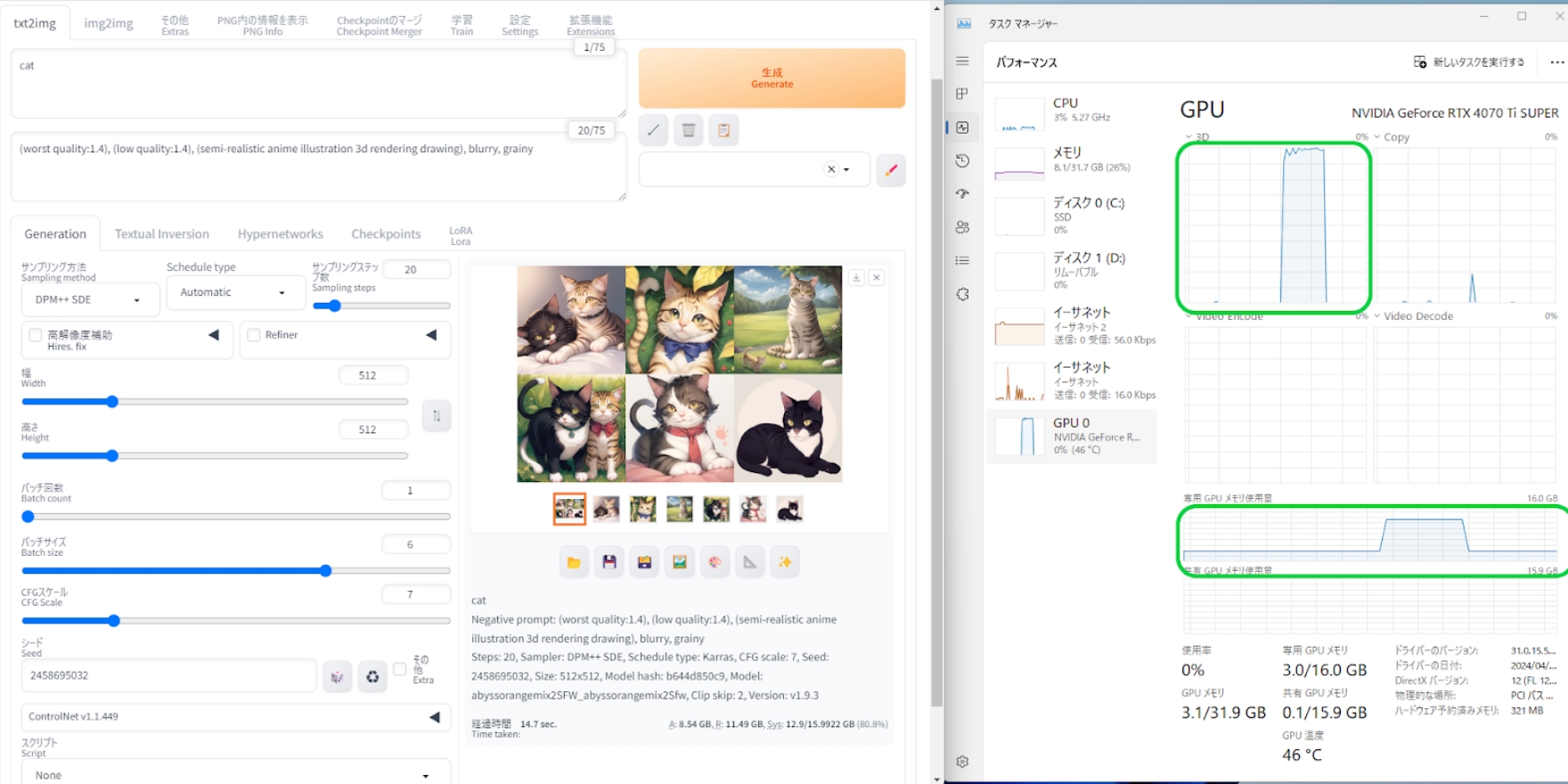
こちらは先程とは違いVRAMを12GB以上使用。6枚分の作業スペースとしてVRAMが機能していることがわかります。描き出し完了後のステータス表示を確認したところ、生成時間は14.7秒となっており、2秒ほど短縮できました。
双方ともに20秒以内で6枚を出力したことには変わりありませんが、時間効率でいえば10%以上の差につながりますので、試行回数を増やすのであればVRAMは多いほうが有利であるということが確認できました。
あとVRAM容量が活きてくるのは、解像度の大きな画像を生成する場合です。これも大きなキャンバスを必要とする作業になるので、作業スペースとなるVRAM容量が重要。
アップスケーリング機能などで補うことはできますが、それでも画像生成AIにおいてVRAM容量が多いほど良いです。VRAM容量が16GBに増強された、RTX4070Ti SUPERを搭載するEFFA E47IMは、画像生成AIに適したゲーミング&クリエイティブPCと言えます。
双方ともに20秒以内で6枚を出力したことには変わりありませんが、時間効率でいえば10%以上の差につながりますので、試行回数を増やすのであればVRAMは多いほうが有利であるということが確認できました。
あとVRAM容量が活きてくるのは、解像度の大きな画像を生成する場合です。これも大きなキャンバスを必要とする作業になるので、作業スペースとなるVRAM容量が重要。
アップスケーリング機能などで補うことはできますが、それでも画像生成AIにおいてVRAM容量が多いほど良いです。VRAM容量が16GBに増強された、RTX4070Ti SUPERを搭載するEFFA E47IMは、画像生成AIに適したゲーミング&クリエイティブPCと言えます。
Q&A
生成AI分野というのは、ここ数年で急速に発展している分野です。その発展速度に法律などの制度が追い付いていないのが現状で、この点が議論の的になる要因の一つとなっています。
特に画像生成AIの場合は、著作権などの権利についての問題が多く指摘されています。円谷プロが中国において著作権侵害で訴えを起こしたケースは既に述べた通りですが、これは比較的分かりやすい権利侵害の一例で、いわゆる偽ブランド品を販売して摘発されるのと同じことです。
ただ誤解しないで頂きたいのは「画像生成AIを使うと訴訟を起こされる」というわけでないということ。良識を持って使う分には咎められることはありません。
とはいえ、これから画像生成AIの利用を考えている方が気になるのは、「AIが生成した画像の著作権は誰のものなのか?」「生成された画像を商用利用する上での注意点は?」この二つではないかと思います。
ここではAIが生成した画像の著作権と商用利用について、深掘りする形で解説したいと思います。
特に画像生成AIの場合は、著作権などの権利についての問題が多く指摘されています。円谷プロが中国において著作権侵害で訴えを起こしたケースは既に述べた通りですが、これは比較的分かりやすい権利侵害の一例で、いわゆる偽ブランド品を販売して摘発されるのと同じことです。
ただ誤解しないで頂きたいのは「画像生成AIを使うと訴訟を起こされる」というわけでないということ。良識を持って使う分には咎められることはありません。
とはいえ、これから画像生成AIの利用を考えている方が気になるのは、「AIが生成した画像の著作権は誰のものなのか?」「生成された画像を商用利用する上での注意点は?」この二つではないかと思います。
ここではAIが生成した画像の著作権と商用利用について、深掘りする形で解説したいと思います。
AIが生成した画像の著作権は
誰のものなのか?
誰のものなのか?
結論から申しますと、誰のものでもない、というのが現在の文化庁の見解です。(2024年6月時点)
基本的には生成AIによって作られた画像は思想又は感情を創作的に表現したものではないため、「著作物には該当しない」という見解をしています。
著作権は人間に付与される権利でAIは人間ではないからです。
逆に人間が思想・感情を創作的に表現するための「道具」として、AIを使用した場合は使用者の著作物になり得る場合があるようです。
では、著作権侵害となるのはどういったケースなのでしょうか。
もちろんAI生成を利用した画像というだけで著作権侵害となることはありません。
文化庁がAI生成の著作権について基準を公表しています。
資料によるとAI生成画像か、AIを利用せずに描かれた画や写真かは著作権侵害の判断基準ではありません。
AI生成か否かに関わらず、他人の著作物に「類似性」「依拠性」が認められるような画像を自分のものとして公開・販売すると著作権侵害になる場合があります。
ポイントとして、
・作風、画風といった雰囲気、アイディア
・ありふれた表現、例えば髪色・表情・ポーズ・構図・傷あと・剣を持っている など多くの作品で採用されている特徴
に関しては類似性があっても著作権侵害にはなりません。
他人の著作物の本質的特徴について相当の類似性、同一性が認められることが重要で、ここが著作権侵害の基準となります。
また、私的に鑑賞するため画像等を生成する行為は、権利制限規定(私的使用のための複製)に該当し、著作権者の許諾なく行うことが可能です。(法第30条第1項)
基本的には生成AIによって作られた画像は思想又は感情を創作的に表現したものではないため、「著作物には該当しない」という見解をしています。
著作権は人間に付与される権利でAIは人間ではないからです。
逆に人間が思想・感情を創作的に表現するための「道具」として、AIを使用した場合は使用者の著作物になり得る場合があるようです。
では、著作権侵害となるのはどういったケースなのでしょうか。
もちろんAI生成を利用した画像というだけで著作権侵害となることはありません。
文化庁がAI生成の著作権について基準を公表しています。
資料によるとAI生成画像か、AIを利用せずに描かれた画や写真かは著作権侵害の判断基準ではありません。
AI生成か否かに関わらず、他人の著作物に「類似性」「依拠性」が認められるような画像を自分のものとして公開・販売すると著作権侵害になる場合があります。
ポイントとして、
・作風、画風といった雰囲気、アイディア
・ありふれた表現、例えば髪色・表情・ポーズ・構図・傷あと・剣を持っている など多くの作品で採用されている特徴
に関しては類似性があっても著作権侵害にはなりません。
他人の著作物の本質的特徴について相当の類似性、同一性が認められることが重要で、ここが著作権侵害の基準となります。
また、私的に鑑賞するため画像等を生成する行為は、権利制限規定(私的使用のための複製)に該当し、著作権者の許諾なく行うことが可能です。(法第30条第1項)
生成された画像を商用利用する上での
注意点は?
注意点は?
まず著作権侵害にならないために生成するモデルの利用に注意しましょう。
上で紹介したCivitaiでモデルの商用利用が可能かどうかを確認しましょう。
加えてクレジット表記の有無の確認も重要です。
上で紹介したCivitaiでモデルの商用利用が可能かどうかを確認しましょう。
加えてクレジット表記の有無の確認も重要です。
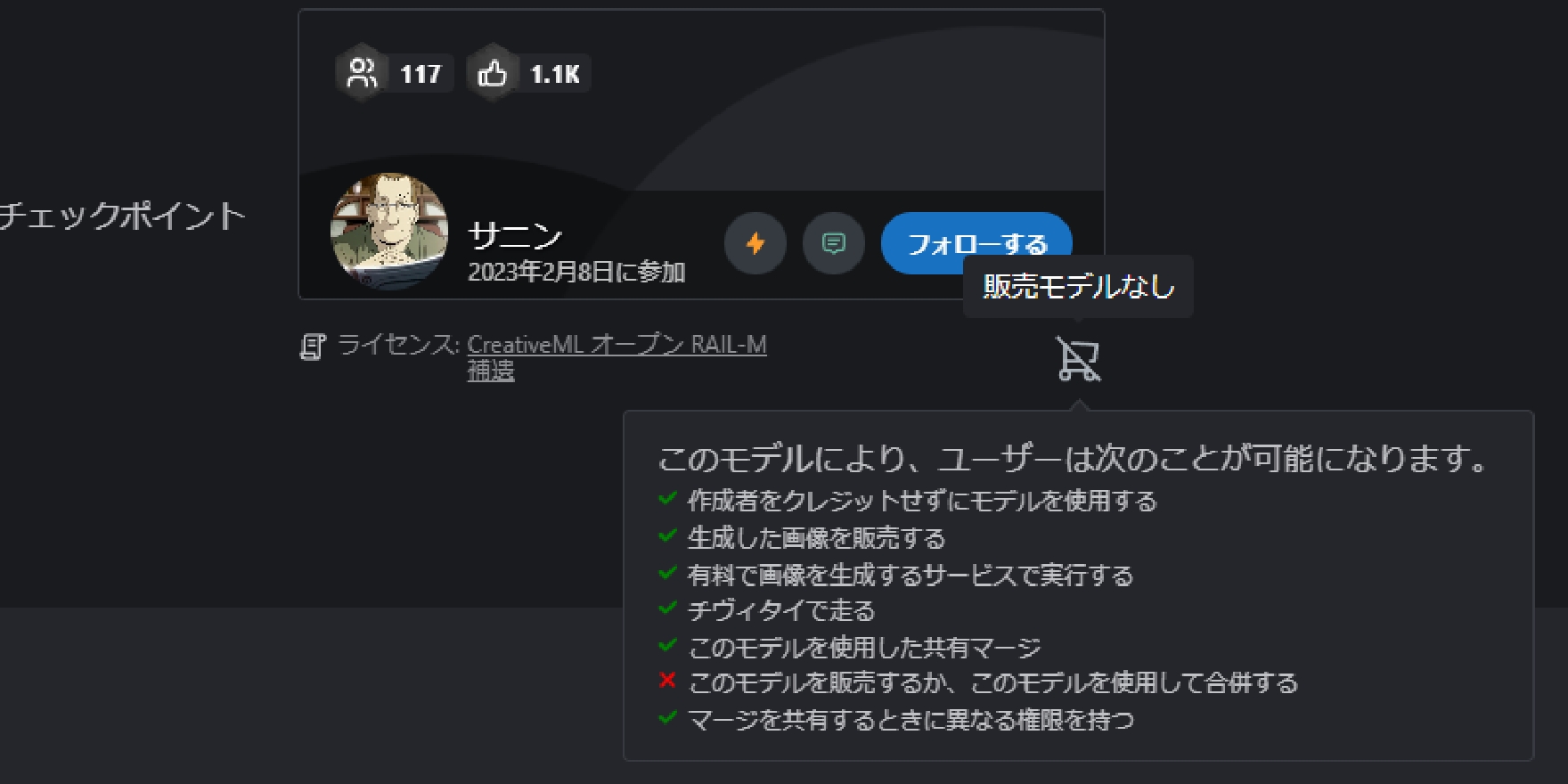
Civitaiのモデル制作者の下にカートのボタンがあります。
ここでライセンス・利用条件などがアイコンで表示されています。マウスポインターを当てることでより詳細な条件を表示できます。
Civitaiはそのままだと英語表記であるため、ブラウザの翻訳機能を使って日本語表記にすると確認しやすいでしょう。
また、商用利用の際はモデルのタイトルやコンセプトに特定の人物や他人の著作物のキャラクター、作品名が挙げられているモデル、LORAなどの利用は避けましょう。
これらのモデルは学習元にベースとなる人物、作品の肖像や著作物が偏って学習されている可能性が高いです。
実在の人物であれば、肖像権を侵害する恐れがあります。
イラスト、アニメ系のモデルであれば意図せず上記の著作物の本質的特徴に類似性、同一性が認められる場合があり、トラブルになりかねません。
また、生成するプロンプトに実在の人物や著作物のキャラクター、作品名を含めて生成することも避けましょう。
生成された画像は画像検索を利用し、類似画像を検索して他人の著作物に類似性がないことを確認しておきましょう。
ここでライセンス・利用条件などがアイコンで表示されています。マウスポインターを当てることでより詳細な条件を表示できます。
Civitaiはそのままだと英語表記であるため、ブラウザの翻訳機能を使って日本語表記にすると確認しやすいでしょう。
また、商用利用の際はモデルのタイトルやコンセプトに特定の人物や他人の著作物のキャラクター、作品名が挙げられているモデル、LORAなどの利用は避けましょう。
これらのモデルは学習元にベースとなる人物、作品の肖像や著作物が偏って学習されている可能性が高いです。
実在の人物であれば、肖像権を侵害する恐れがあります。
イラスト、アニメ系のモデルであれば意図せず上記の著作物の本質的特徴に類似性、同一性が認められる場合があり、トラブルになりかねません。
また、生成するプロンプトに実在の人物や著作物のキャラクター、作品名を含めて生成することも避けましょう。
生成された画像は画像検索を利用し、類似画像を検索して他人の著作物に類似性がないことを確認しておきましょう。
まとめ
画像生成AI「Stable Diffusion」はオープンソースAIであり、利用料を払うサブスクリプションサービスの他、自前のPC環境に導入してローカル環境でも利用可能です。
ローカル環境導入には必要となるPCの選定、経済的・技術的ハードルが少々高くなりますが、ハードウェア・ソフトウェア両面での技術的進歩により、今後はそのハードルも下がるのではないかと思われます。
より生成AIが一般に認知されるようになりましたが、一方で生成AIが悪用されるケース、それに伴って訴訟に発展するケースもあり、生成AIを取り巻く法整備が遅れているのも事実です。
ただ良識を持って活用すれば、画像生成AIは大変便利なツールとなります。単純に画像を生成するというのも楽しいですが、クリエイティブ現場で新しい素材やアイディアの入手手段にされるなど、既に有益に活用される例もあります。
まだまだ発展途上の分野であるだけに、Web上でも情報が散見される状態。有志によるまとめサイトや、コミュニティーなどもありますので、そういったところでの交流も含めた新しい文化として楽しんでいただければと思います。
ローカル環境導入には必要となるPCの選定、経済的・技術的ハードルが少々高くなりますが、ハードウェア・ソフトウェア両面での技術的進歩により、今後はそのハードルも下がるのではないかと思われます。
より生成AIが一般に認知されるようになりましたが、一方で生成AIが悪用されるケース、それに伴って訴訟に発展するケースもあり、生成AIを取り巻く法整備が遅れているのも事実です。
ただ良識を持って活用すれば、画像生成AIは大変便利なツールとなります。単純に画像を生成するというのも楽しいですが、クリエイティブ現場で新しい素材やアイディアの入手手段にされるなど、既に有益に活用される例もあります。
まだまだ発展途上の分野であるだけに、Web上でも情報が散見される状態。有志によるまとめサイトや、コミュニティーなどもありますので、そういったところでの交流も含めた新しい文化として楽しんでいただければと思います。